Document Object Model Level 2 Core
- INFO
- 2026-06-27
* 본 글은 W3C에서 작성한 DOM 표준 명세 중 Level 2 - Core를 번역한 HTML 공부를 위한 목적으로 시작한 번역으로, 시간과 체력 관계상 XML 관련 내용은 넘어간 것이 많습니다.
* 각 인터페이스의 경우, IDL 정의를 비롯한 자세한 내용이 생략되어있으며, 특성과 메서드만 목록화하였습니다. 자세한 구현 내용은 원문을 검색해주세요.
* 혹-시나, 상업적 용도로 사용하지 말아주세요.
문서 객체 모델(DOM)이란 HTML과 XML 문서를 위한 응용 프로그램 개발 인터페이스(API)이다. DOM은 문서의 논리적 구조, 문서가 접근되고 조작되는 방식을 정의한다. DOM 기술에서, 용어 "문서"는 넓은 의미로 쓰인다. 점점, XML은 여러 시스템에서 보관되는 다양한 종류의 정보를 표현하는 하나의 방식으로 사용되고 있다. 또한 대부분의 XML은 전통적으로 문서라기보다는 데이터로서 여겨져왔다. 그럼에도 불구하고, XML은 문서를 통해 데이터를 제시하고, DOM은 이러한 데이터를 다루기 위해 사용된다.
DOM을 통해 개발자는 문서를 구축하고, 그 구조를 다룰 수 있게 되며, 요소나 컨텐츠를 더하거나 수정, 삭제할 수 있다. DOM을 통해 HTML 및 XML 문서에서 발견된 무엇이든지 접근하거나, 수정하거나, 삭제하거나, 새로 추가할 수 있는 것이다. 다만 몇 가지 예외는 있다 - 특히, XML의 내/외부 하위셋에 대한 DOM 인터페이스는 아직 정해지지 않았다.
W3C 명세에 있어 DOM을 위한 중요한 목표 중 하나는 다양한 환경과 응용 프로그램에서 사용될 수 있는 표준 프로그래밍 인터페이스를 제공하는 것이다. DOM은 어떤 프로그래밍 언어와도 사용될 수 있도록 디자인되었다. 정확하면서도 특정 언어에 종속되지 않은 DOM 인터페이스 명세를 제공하기 위해, 우리는 CORBA 2.2 명세에서 정의된 바와 같이 OMG IDL을 이용하여 명세를 정의하기로 결정하였다. OMG IDL 명세에 더하여, 우리는 Java와 ECMAScript에 대한 언어 바인딩도 제공한다.
알아두기: OMG IDL은 오로지 인터페이스 명세에서 특정 언어에 종속되지 않고, 중립적인 구현을 하는 데에만 사용된다. 기타 다양한 IDL 역시 사용될 수 있다. 보통 IDL은 특정 컴퓨팅 환경을 대상으로 디자인된다. DOM은 어떤 컴퓨팅 환경에서도 구현될 수 있고, 특정 IDL에 연관된 객체 바인딩 런타임을 요구하지 않는다.
DOM은 이 표를 아래와 같이 표현한다.
DOM에서는, 문서는 트리와 유사한 모습의 논리적 구조를 갖는다. 더 정확하게 말하자면, 한 개 이상의 트리를 갖고 있는 "Forest" 자료 구조와 닮았다. 하지만 DOM은 문서가 트리 또는 포레스트로 구현되어야 한다고 규정하고 있지 않으며, 객체 간의 관계가 어떻게 구현되어야하는지를 규정하고 있지도 않다. DOM은 어떤 편리한 방식으로 구현되어도 상관없는 논리적 모델이다. 이 정의에서 우리는 구조 모델이라는 용어를 사용하여, 트리와 닮은 모양으로 문서를 표현하는 것을 설명한다. DOM 구조 모델의 한 가지 중요한 속성은 구조적 동형률(Structural Isomorphism)이다. 만약 두 DOM 구현이 동일한 문서를 표현하고자 한다면, 두 구현 결과물은 동일한 구조 모델을 생성할 것이며, 두 모델은 XML 정보 집합에 의거하여 정확하게 동일한 객체들과 관계들로 이루어질 것이다.
알아두기 : DOM을 구축하는 데에 사용한 파서에 따라 다양한 변형이 존재한다. 예를 들어, 파서가 삭제할 경우 DOM은 요소 내의 공백을 포함하지 않을 수도 있다.
"문서 객체 모델"은 전통적인 객체 지향 디자인 측면에서 볼 때 "객체 모델"이기 때문에 이와 같은 이름이 지어졌다. 여기서 문서는 객체를 이용하여 모델링되며, 이 모델은 문서의 구조뿐만 아니라, 문서와 문서 안의 요소들의 행동을 모두 아우른다. 즉, 위의 도형에서 노드들은 자료구조를 나타내는 것이 아니라, 제각기 기능과 식별성을 지닌 객체를 나타낸다. 객체 모델로서, DOM은 아래와 같은 사항들을 알려준다.
- 문서를 나타내고 조작하는 데에 사용되는 인터페이스와 객체
- 이러한 인터페이스와 객체에 대한 의미론 / 행위와 속성 포함
- 이러한 인터페이스와 객체들 간의 관계와 공동의 결과
전통적으로 SGML 문서의 구조는 객체 모델이 아닌 추상 데이터 모델로 표현되었다. 추상 데이터 모델에서는, 모델은 데이터 중심으로 형성된다. 객체 지향 프로그래밍 언어에서는, 데이터는 데이터를 캡슐화하여 숨기는 객체 내부에 들어 있어서 직접적인 외부 조작으로부터 보호된다. 이러한 객체들과 관련된 함수들은 객체들이 조작되는 방식을 결정하며, 이 또한 객체 모델의 일부이다.
본 섹션에서는 다른 시스템과 구별하는 것을 통해 DOM에 대한 정확한 이해를 제공한다.
- DOM은 이진법으로 작성된 명세가 아니다. 동일한 언어로 작성된 DOM 프로그램은 이에 호환되는 다른 플랫폼에서도 소스 코드로서 작동하겠지만, DOM은 어떠한 형태의 이진 연산도 정의하고 있지 않다.
- DOM은 XML 또는 HTML이 객체를 사용하게끔 하는 것이 아니다. 객체들이 XML에서 표현되는 방식을 규정하는 대신, DOM은 XML과 HTML 문서가 객체로서 어떻게 표현되는지를 규정하여 객체 지향 프로그램에서 사용될 수 있도록 한다.
- DOM은 자료구조가 아니라, 인터페이스를 규정하는 객체 모델이다. 비록 본 문서에서 부모/자식 관계를 나타내는 모형을 사용하고 있기는 하지만, 이것은 프로그래밍 인터페이스가 규정하는 논리적 관계이며, 특정 내부 자료구조를 표현한 것이 아니다.
- DOM은 XML 또는 HTML의 "진정한 내무 의미론"을 규정하지 않는다. XML과 HTML의 언어 의미론은 해당 언어들에 대한 W3C 권고안에서 규정된다. DOM은 그러한 의미론들을 모두 수용할 수 있도록 디자인된 프로그래밍 모델이다. DOM은 XML과 HTML 문서를 작성하는 방법에 대해 상관하지 않는다. 해당 언어로 작성된 어떤 문서든 DOM을 통해 표현될 수 있다.
- 비록 이름이 이렇긴 하지만, DOM은 구성 요소 객체 모델(Component Object Model)이 경쟁 상대가 아니다. COM은 CORBA와 마찬가지로 인터페이스와 객체를 규정하는 언어 독립적 방법이다. DOM은 HTML 및 XML 문서를 다룰 수 있도록 디자인된 인터페이스와 객체의 집합이다. DOM은 COM과 CORBA와 같은 언어 독립적 시스템을 이용하여 구현될 수 있다. 또한 Java, ECMAScript와 같은 특정 언어에 종속된 구현도 가능하다.
DOM은 JavaScript 스크립트와 Java 프로그램이 웹 브라우저들 간에 포팅하고자 하는 의도에서 비롯되었다. "동적 HTML"은 DOM의 직계 조상이며, 처음에는 브라우저 차원의 발상이었다. 하지만 W3C에 DOM 작업 그룹이 형성되고 난 뒤, 이 그룹은 HTML 및 XML 에디터 또는 문서 저장소 등을 포함하는 다른 영역의 판매 회사들도 참여하게 되었다. 이 판매사들 중 몇몇은 XML이 개발되기 이전에 SGML을 이용하기도 했다. 그 결과 DOM은 SGML 계열과 HyTime 표준의 영향을 받게 되었다. 일부 판매사들은 SGML/XML 에디터 또는 문서 저장소에 API를 제공하기 위하여 자사 고유의 객체 모델을 개발하기도 하였는데, 이 또한 DOM에 영향을 끼쳤다.
기본적인 DOM 인터페이스에는 엔티티를 나타내는 객체가 존재하지 않는다. 숫자형 문자 참조. HTML과 XML에서 미리 정의된 엔티티에 대한 참조는 엔티티의 교체를 메꾸는 단일 문자로 대체된다. 예를 들어 아래의 코드를 보자.
"&"는 문자 "&"로 대체되며, P 요소 내의 텍스트는 단일한 연속 문자열을 형성한다. 숫자형 문자 참조와 미리 정의된 엔티티는 HTML 상의 CDATA 섹션, SCRIPT 또는 STYLE 요소에서는 인식되지 않기 떄문에, 본래 의도로 생각되는 단일 문자들로 대체되지 않는다. 예시 코드가 CDATA 섹션으로 둘러쌓여있다면, "&"는 대체되지 않을 것이고, <p>는 시작 태그로 인식되지 않을 것이다. 내부든 외부든 일반적인 엔티티에 대한 표현은 Level 1 명세의 XML 인터페이스 상에 정의되어 있다.
알아두기: 문서의 DOM 표현이 XML 또는 HTML 텍스트 문자열이라면, 응용 프로그램은 텍스트 데이터 내의 각 문자를 검사하여 숫자 참조 또는 미리 정의된 엔티티로 교체할 필요가 있는지 파악해야 한다. 이에 실패할 경우 HTML 또는 XML를 제대로 출력할 수 없게 된다. 또한, 인코딩에 존재하지 않는 문자가 마크업 또는 CDATA 섹션에 존재할 경우, ISO 10646을 충족하지 않는 문자 인코딩("charset")으로 문자열을 만드는 작업은 실패할 수도 있다는 점을 구현할 때 인지하고 있어야 한다.
본 섹션은 DOM Level 2 준수 정도에 대해 설명한다. DOM Level 2는 14개 모듈로 구성되어있다. DOM Level 2 또는 DOM Level 2 모듈을 준수하는 것이 가능하다.
구현체가 DOM Level 2를 준수한다고 함은, 본 문서에서 규정하는 Core 모듈을 지원하는 것이다. 또한 구현체가 DOM Level 2를 준수한다고 함은 모듈을 위한 인터페이스, 그리고 모듈과 관련된 의미론을 위한 인터페이스를 지원하는 것이다.
아래의 리스트는 DOM Level 2 모듈과 그 모듈이 사용하는 기능들이다. 기능들은 대소문자를 구분하지 않는다.
- Core module
- XML module
- HTML module
- Views module
- Style Sheets module
- CSS module
- CSS2 module
- Events module
- UI Events module
- Mutation module
- HTML Events module
- Range module
- Traversal module
DOM 구현체는 DOMImplementation 인터페이스의 hasFeature(feature, version) 메서드에 대해 대응하는 기능이 모듈을 구현하고 있지 않다면 true를 반환해선 안 된다. DOM Level 2.0에 속한 기능들에 대해 사용되는 숫자 version은 "2.0"이다.
DOM은 XML 및 HTML 문서를 다루는 데에 어떤 인터페이스가 사용되는지 규정한다. 이러한 인터페이스는 마치 C++의 "추상 기반 클래스"와 같이 추상화이다. 즉, 어떤 문서에 대한 응용 프로그램의 내부 표현에 접근하고 조작하는 수단이다. 인터페이스는 구체적인 구현을 암시하고 있지 않다. 각 DOM 응용 프로그램은 문서를 어떤 방식으로든 표현할 수 있으며, 본 명세에 제시된 인터페이스가 지원되기만 하면 된다. 일부 DOM 구현물은 DOM 명세가 만들어지기도 전에 작성된 소프트웨어에 접근하기 위한 DOM 인터페이스를 사용하는 구닥다리 프로그램이다. 따라서 DOM은 구현 의존성을 피하도록 디자인되었다. 아래의 사항은 특히 강조하는 부분이다.
- Attributes defined in the IDL do not imply concrete objects which must have specific data members - in the language bindings, they are translated to a pair of get()/set() functions, not to a data member. (Read-only functions have only a get() function in the language bindings).
- DOM 응용 프로그램은 본 명세에는 없는 추가적인 인터페이스와 객체를 제공할 수 있으며 여전히 DOM 표준을 준수하는 것이다.
- 인터페이스를 규정하고 실제 생성되는 객체를 규정하지 않기 때문에, DOM은 구현을 위하여 어떤 생성자를 호출할 것인지 알지 못한다. 보통 DOM 사용자는 createXXX() 메서드를 Document 클래스에 대해 사용하여 문서 구조를 생성하고, DOM 구현체는 해당 구조에 대한 내부 표현을 createXXX() 함수 코드로 작성한다.
Level 1 인터페이스는 Level 1과 Level 2 기능을 모두 지원하기 위해 확장되었다.
Java 또는 ECMAScript를 제외한 나머지 언어를 위한 DOM 구현체는 해당 언어와 런타임을 위해 자연스럽고 적절한 바인딩을 선택해야한다. 예를 들어, 일부 시스템은 Document를 상속받고 새 메서드와 특성을 포함하는 Document2 클래스를 생성해야 할 수도 있다.
DOM Level 2는 멀티스레딩 메커니즘을 정의하지 않는다.
본 섹션에서는 문서 객체에 접근하고 조작하기 위한 최소한도의 객체와 인터페이스 집합을 정의한다. 본 섹션에서 정의된 기능성(핵심 기능성)은 소프트웨어 개발자과 웹 스크립트 개발자들이 표준을 준수하는 제품 속의 HTML과 XML 코드를 파싱한 결과물에 접근하고 조작하는 데에 충분할 것이다. The DOM Core API also allows population of a Document object using only DOM API calls; Document를 로드하고 저장하는 방법은 DOM API를 구현하는 제품에게 맡긴다.
DOM은 문서를 Node 객체의 계층 구조로서 제시하며, 여기서 Node 객체는 다른 특화된 인터페이스를 구현하기도 하는 객체이다. 일부 타입의 노드는 다양한 타입의 또다른 자식 노드를 가지며, 또 어떤 노드는 문서 구조 상에서 다른 자식을 가질 수 없는 리프 노드이다. 노드의 타입과, 각 타입들이 가질 수 있는 자식의 타입들은 아래와 같다.
- Document : Element(Maximum of one), ProcessingInstruction, Comment, DocumentType
- DocumentFragment : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- DocumentType : 자식 없음
- EntityReference : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- Element : Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference
- Attr : Text, EntityReference
- ProcessingInstruction : 자식 없음
- Comment : 자식 없음
- Text : 자식 없음
- CDATASection : 자식 없음
- Entity : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- Notation : 자식 없음
DOM은 NodeList 인터페이스를 규정하여 Node로 이루어진 순서가 있는 리스트를 처리할 수 있다. 이러한 리스트의 예로는 Node의 자식들, Element.getElementsByTagName 메서드에 의해 반환되는 요소들이 있다. 또한 DOM은 NamedNodeMap 인터페이스를 규정하여 순서가 없는 Node들의 집합을 처리할 수 있다. 이 집합의 내부 항목들은 각각이 갖고 있는 name 특성을 통해 참조될 수 있다. 이러한 집합의 예로는 Element의 attribute들이 있다. DOM의 NodeList와 NamedNodeMap은 "Live 상태"이다. 즉, 기반이 되는 문서 구조에 대한 변화가 관련 NodeList와 NamedNodeMap에 반영된다는 것이다. 예를 들어, DOM 사용자가 Element의 자식 객체로 이루어진 NodeList 객체를 얻고, 최종적으로 해당 요소에 추가적인 자식을 추가하거나, 수정 또는 제거하였다고 하자. 이떄 이러한 변경점은 사용자의 추가적인 작업 없이 자동으로 NodeList에 반영된다는 것이다. 같은 방식으로, 어떤 Node에 대한 변경점은 Node를 가리키는 모든 참조에 반영된다.
명세를 통해 정의된 대부분의 API들은 클래스가 아닌 인터페이스이다. 즉 실제 구현을 할 경우, 미리 규정된 이름과 정해진 작동 방식을 메서드와 함께 노출시킬 뿐이지, 해당 인터페이스와 직접 대응하는 클래스를 실제로 구현하는 것이 아니다. 이를 통해 DOM API는 마치 베니어 합판처럼, 레거시 응용 프로그램이 갖는 자료구조를 유지하면서 그 위에 얇게 구현될 수 있도록 해준다. 혹은 다른 클래스 구조를 지닌 새로운 프로그램 위에 얇게 구현될 수 있도록 해준다. 이것은 또한 Java 또는 C++의 경우와는 달리, 기존의 생성자로는 DOM 객체를 생성할 수 없다는 것이다. 왜냐하면 기반 객체를 생성할 (응용 프로그램의) 생성자는 DOM 인터페이스와는 아무 관련이 없을 것이기 때문이다. 객체 지향 디자인에서 이에 대한 전통적인 해결책은 다양한 인터페이스를 구현하는 객체 인스턴스를 만들 수 있는 factory메서드를 정의하는 것이다. 어떤 인터페이스 'X'를 구현하는 객체는 Document 인터페이스의 "CreateX()" 메서드로 생성한다. 이것은 모든 DOM 객체는 특정 문서의 문맥 위에서 존재하기 때문이다.
DOM Level 2 API는 DOMImplementation 또는 Document 객체를 만드는 표준적 방법을 규정하지 않는다. 실제 DOM 구현체는 이러한 인터페이스를 구현하는 독점적 방법을 제공해야 한다. 그래야 다른 객체들이 Document의 Create 메서드를 통해 구축될 수 있다.
Core DOM API는 다양한 언어에 호환되도록 디자인되었으며, 여기에는 평이한 난이도의 스크립트 언어와 전문 개발자가 사용하는 고난이도 언어를 포함한다. 즉, DOM API는 다양한 메모리 관리 철학에 상관없이 작동해야 한다. 이를테면 생성자를 명시적으로 제공하지만 자동 카비지 콜렉션 메커니즘을 제공하여 메모리 관리를 사용자에게 전혀 노출하지 않는 Java같은 언어 플랫폼부터, 개발자로 하여금 명시적으로 객체 메모리를 할당하고 사용 상황을 추적하여 명시적으로 해제까지 해야하는 C++과 같은 언어까지 다양하게 대응해야 한다. 다양한 플랫폼에 대해 일관성있는 API를 보장하기 위해, DOM은 메모리 관리 문제를 일절 다루지 않고, 구현 단계에 맡긴다. DOM 작업 그룹이 고안한 언어 바인딩 중 그 어떤 것도 메모리 관리 메서드를 요구하지 않는다. 하지만 다른 언어를 위한 DOM 바인딩은 이에 관한 지원을 할 것이다. 이러한 확장은 DOM API를 특정 언어로 포팅하는 사람들의 책임이며, DOM 작업 그룹이 다룰 사안이 아니다.
특성과 메서드 이름이 짧고, 정보를 전달하고, 내부적으로 일관성을 유지하며, 비슷한 API를 사용하는 사용자에게 친숙하다면 좋겠지만, 한편으로는 DOM 구현체가 지원하는 레거시 API의 이름과 충돌해서는 안 된다. 더 나아가 OMG IDL과 ECMAScript는 이름이 겹치지 않으면서 친숙하게 짧게 만들기에는, 다양한 네임스페이스들 사이에서 명확성을 부여하기가 어렵다. 따라서 다양한 환경을 아우르며 유일성을 지니기 위해, DOM의 명칭들은 길고 서술성이 짙은 경향이 있다.
DOM 작업 그룹은 다양한 용어를 사용하는 데에 있어 내부적으로 일관되고자 노력해왔다. 비록 다른 API에서는 쉽게 보기 힘든 구분법이지만 말이다. 예를 들어, "remove"라는 이름은 메서드가 구조적 모델에 변화를 가할 때에 사용하고, "delete"는 구조적 모델 차원에서 메서드가 무언가를 제거할 때에 사용한다. Delete되는 것은 복구할 수 없다. Remove되는 것은 이치에 맞다면 다시 복구할 수 있다.
DOM Core API는 XML/HTML문서에 왠지 다른 2개의 인터페이스 집합을 제공한다. 상속 계층구조를 통한 "객체 지향적" 접근, 그리고 형변환이 없이 노드 인터페이스 또는 쿼리 인터페이스 호출를 사용하여 조작할 수 있도록 하는 "단순화된" 시점이다. 이 동작들은 Java와 COM에서는 꽤 고비용 동작이며, DOM은 성능이 중요한 환경에서 사용될 수도 있기 때문에, 중요한 기능을 동작하는 데에 있어 노드 인터페이스만을 이용하게끔 한다. DOM을 대하는 데에 있어 "모든 것은 노드이다"라는 접근보다는 상속 구조를 더 이해하기 쉽게 느낄 것이기 때문에, 객체지향 API를 선호하는 사람들을 위해 고레벨 인터페이스를 제공한다.
이것은 API에 반복이 많다는 뜻이다. DOM 작업 그룹은 "상속" 접근을 API를 대하는 주된 관점으로 삼고, Node에 대한 모든 기능들은 "추가적인" 기능으로 간주한다. But that does not eliminate the need for methods on other interfaces that an object-oriented analysis would dictate. 물론, 객체 지향적 분석이 Node 인터페이스에 존재하는 것과 겹치는 특성 또는 메서드를 낳는다면, 그것을 두고 반복이라고 말하지는 않는다. 따라서, Node 인터페이스에 nodeName이라는 흔한 특성이 있다고 하더라도, Element 인터페이스에도 여전히 tagName이라는 특성이 존재한다. 이 두 특성은 같은 값을 갖겠지만, DOM 작업 그룹은 DOM API가 지원해야 하는 여러 상황을 모두 고려했을 때 두 가지 상황 모두를 지원하는 것이 바람직하다고 생각했다.
상호동작성을 보장하기 위해, DOM은 DOMString이라는 타입을 아래와 같이 정의한다.
- DOMString은 16bit 크기의 문자로 이루어진 문자열로, IDL로 표현하면 다음과 같다.
typedef sequence<unsigned short> DOMString;
- 응용 프로그램은 DOMString을 UTF-16을 이용하여 인코딩해야한다. UTF-16은 실제 산업 현장에서 널리 쓰이고 있기 때문에 채택되었다. HTML, XML은 모두 문서 문자 세트가 UCS-4를 기반으로 두고 있다. 따라서 단일 숫자형 문자 참조는 때로는 DOMString에서 2개 칸을 차지하기도 한다.
알아두기: DOM은 string 타입의 이름을 DOMString으로 정의하고 있지만, 바인딩은 다른 이름을 사용할 수도 있다.
상호동작성을 보장하기 위해, DOM은 DOMTimeStamp라는 타입을 아래와 같이 정의한다.
- DOMTimeStamp는 밀리초를 숫자로 표현한다.
알아두기 : DOM은 DOMTimeStamp 타입을 사용하긴 하지만, 바인딩은 다른 타입을 사용할 수 있다. Java의 예를 들면, DOMTimeStamp는 long 타입으로 바인드된다. ECMAScript의 경우, TimeStamp는 Data 타입으로 바인드되는데, 왜냐하면 integer 타입의 범위가 너무 작기 때문이다.
DOM은 문장 매칭을 담고 있는 인터페이스를 많이 갖고 있다. HTML 프로세서는 보통 대문자 일반화를 가정하여 요소 등의 이름을 다룬다. 반면 XML은 명시적으로 대소문자를 구분한다. DOM에 있어 string 매칭은 16bit 크기인 개별 문자 코드 하나하나에 대하여 이루어진다. 이처럼 DOM은 DOM 구조가 구축되기 전에 프로세서에서 어떤 형태의 일반화가 이루어질 것으로 가정한다.
이것은 어떤 일반화가 발생하는지의 문제를 제기하게 된다. W3C I18N 그룹은 DOM을 구현하는 응용 프로그램에 대해 어떤 일반화가 필요한지를 규정하는 과정을 수행하고 있다.
DOM Level 2는 DOM Level 1의 여러 인터페이스들을 보강하여 XML 네임스페이스를 지원한다. 이를 통해 네임스페이스와 관련된 요소와 특성들을 생성하고 조작할 수 있다.
DOM과 관련한 한,
<-------------미완성--------------->
본 섹션에 포함된 인터페이스는 근본으로 간주되며, 표준을 준수하는 모든 DOM 구현체는 HTML DOM구현과 더불어 이를 모두 구현해야 한다.
> Exception DOMException
DOM 동작은 오직 "예외적" 상황에서 - 예를 들어 동작을 수행하는 것이 불가능할 경우(논리적 이유, 데이터 소실, 구현이 불안정함 등) - 만 예외를 던진다. 보통 DOM 메서드는 본래의 처리 상황 속에서 특정 오류값을 반환한다. 예를 들면 NodeList를 사용하고 있을 때 out-of-bound 오류를 반환하는 것이다.
구현체는 다른 상황에는 다른 예외를 던질 것이다. 예를 들어 null 인자가 전달되었을 경우, 구현체는 구현 의존적인 예외를 던질 것이다.
어떤 언어나 객체 시스템은 예외라는 개념을 지원하지 않는다. 그러한 시스템에 대해서는, 네이티브 오류 보고 메커니즘을 사용하여 오류 조건을 가리켜야 한다. 예를 들어 어떤 바인딩의 경우, 메서드는 대응하는 메서드 설명에 존재하는 것과 유사한 오류 코드를 반환한다.
> Interface DOMImplementation
DOMImplementation 인터페이스는 DOM의 특정 인스턴스에 독립적인 동작을 위한 메서드들을 제공한다.
DOM Level 1에서는 document 인스턴스를 생성하는 방법을 규정하지 않는다. 따라서 document 생성은 구현체를 위한 작동이다. 차후의 DOM Level 정의에서 document를 직접 생성하는 메서드를 제공할 것으로 기대된다.
- 메서드
createDocument : // DOM Level 2에 추가
// XML 전용
createDocumentType : // DOM Level 2에 추가
// XML 전용
hasFeature : DOM 구현체가 특정 기능을 구현하고 있는지 검사
> Interface DocumentFragment
DocumentFragment는 "가벼운" 또는 "최소한의" Document 객체이다. 문서 트리의 일부만 추출하거나, 문서의 일부분을 생성하는 것은 종종 필요한 작업이다. 일부분만 이동하여 문서를 재배열하거나 자르기의 사용자 명령을 구현한다고 상상해보자. 이러한 일부분을 포함하는 객체를 갖는 것은 바람직하며 이러한 목적을 위해 Node를 사용하는 것은 자연스럽다. Document 객체가 이러한 역할을 충족할 수 있기는 하지만, Document 객체는 기반하는 구현제에 따라 잠재적으로 아주 무거운 객체가 될 수 있다. 아주 가벼운 객체가 필요한 것이다. DocumentFragment는 그러한 객체이다.
더 나아가, 다양한 동작 - 예를 들어, 다른 노드(A)에 자식으로서 노드를 삽입하기 - 은 DocumentFragment 객체를 인자로서 사용할 수 있다. 이 통해 DocumentFragment의 자식 노드들이 모두 이 노드(A)의 자식 리스트로 이동될 수 있다.
DocumentFragment 노드의 자식들은 0개 이상의 노드로, 문서 구조를 정의하는 어떤 서브트리의 루트일 수 있다. DocumentFragment 노드는 잘 정리된 XML 문서일 필요는 없다. 예를 들어, DocumentFragment는 단 하나의 자식만 가지며, 그 자식 노드는 Text 노드일 수 있다. 이러한 구조 모델은 HTML 문서와 XML 문서 모두 대응되지 않는다.
DocumentFragment가 Document(또는 자식을 받을 수 있는 다른 노드)에 삽입되면 DocumentFragment의 자식들은 해당 Node로 삽입되지만, DocumentFragment 자신은 삽입되지 않는다. 이것은 DOM 사용자가 형제 노드를 만들고 싶을 때 유용하게 사용할 수 있다. DocuentFragment는 노드들의 부모로서 작용하며, 사용자는 insertBefore(), appendChild() 등 Node 인터페이스의 표준 메서드들을 사용할 수 있다.
> Interface Document
Document 인터페이스는 HTML 또는 XML 문서 전체를 표현한다. 개념적으로 이것은 문서 트리의 루트에 해당하며, 문서의 데이터에 대한 가장 빠른 접근을 제공한다.
element, text node, comment, processing instruction 등은 Document의 문맥을 벗어나서 존재할 수 없기 때문에, Document 인터페이스는 이러한 객체들을 생성하는 데에 필요한 factory 메서드를 갖고 있다. 생성된 Node 객체는 ownerDocument 특성을 가지며, 이를 통해 그들이 생성된 문맥 안에서 Document와 연결된다.
- 특성
doctype : 해당 문서와 관련된 문서 타입 선언. 문서 타입 선언이 없다면 null을 반환한다. DOM Level 1은 문서 타입 선언 변경을 지원하지 않으므로, docType은 변경될 수 없다.
implementation : 해당 문서를 다루는 DOMImplementation 객체. DOM 응용 프로그램은 다양한 구현체로부터 객체를 제공받아 사용할 것이다.
documentElement : 문서의 루트 요소이자 Document의 자식 노드로 직접 접근을 허용하는 편의 상의 특성. HTML 문서라면, 이것은 tagName으로 "HTML"을 갖는 요소이다.
- 메서드
createElement : 정의된 타입의 요소를 생성한다. 반환된 인스턴스는 Element 인터페이스를 구현한 것으로, 따라서 반환된 객체에는 특성이 직접 지정될 수 있다.
또한 디폴트값이 정해진 특성이 있다면, 이를 표현하는 Attr 노드가 자동으로 생성되고 요소에 추가된다.
한정자와 네임스페이스 URI로 요소를 만들고 싶다면, createElementNS 메서드를 사용하자.
createElementNS : // XML 전용
createDocumentFragment : 공백인 DocumentFragment 객체를 생성한다.
createTextNode : 주어진 string을 받아 텍스트 노드를 생성한다.
createComment : 주어진 string을 받아 코멘트 노드를 생성한다.
createCDATASection : 주어진 string을 받아 CDATASection 노드를 만든다. // HTML 미지원
createProcessingInstruction : 주어진 이름과 데이터를 받아 ProcessingInstruction 노드를 생성한다. // HTML 미지원
createAttribute : 주어진 이름의 Attr을 생성한다. Attr 인스턴스는 setAttribute 메서드를 이용하여 요소에 적용될 수 있다.
createAttributeNS : // DOM Level 2에 추가
// XML 전용
createEntityReference : EntityReference 객체를 생성한다 // HTML 미지원
getElementById : // DOM Level 2에 추가
인자로 주어진 elementID를 가진 요소를 반환한다. 만약 그러한 요소가 존재하지 않으면 null을 반환한다. 동일 ID를 가진 요소가 1개 이상일 때의 작동을 정의하지 않는다.
알아두기 : DOM 구현체는 어떤 특성이 ID 타입인지에 대한 정보를 갖고 있어야 한다. 따로 정의된 것이 아니라면, "ID"라는 이름을 가진 특성은 ID 타입이 아니다. 특성이 ID 타입인지 여부를 구현체가 알지 못하면 null을 반환할 것으로 예상한다.
getElementsByTagName : 주어진 태그명과 일치하는 요소들로 이루어진 NodeList를 반환한다. 이때 순서는 Document 트리에 대해 전위 순회를 했을 경우의 순서이다.
getElementsByTagNameNS : // DOM Level 2에 추가
주어진 local name과 네임스페이스 URI를 가진 모든 요소로 이루어진 NodeList를 반환한다. 이때 순서는 Document 트리에 대해 전위 순회를 했을 경우의 순서이다.
importNode : // DOM Level 2에 추가
다른 문서에서 해당 문서로 노드를 가져온다. 반환되는 노드는 부모가 없다. 즉, parentNode가 null을 갖는다. 다른 문서에 있는 원본 노드는 변형되거나 제거되는 것이 아니라, 본 메서드를 통해 원본 노드의 복제본을 생성하는 것이다.
모든 노드에 대해, 노드를 import하는 동작은 import를 수행하는 문서가 소유하게 될 새로운 노드 객체를 생성하게 된다. 이때 원본 노드가 갖고 있는 특성들, nodeName, nodeType, 네임스페이스와 관련된 특성들 - prefix, localName, namespaceURI 등 - 을 모두 동일하게 가져오게 된다. Node 인터페이스의 cloneNode과 마찬가지로, 원본 노드는 변경되지 않는다.
추가적인 정보는 nodeType에 따라 적절하게 복사되며, 이는 원본 문서에 있던 XML 또는 HTML의 일부분이 다른 문서로 복사되었을 때 예상되는 동작을 모방하여 구현하기 위함이다. XML의 경우에 두 문서가 서로 다른 DTD를 가질 수 있음을 인식하는 것이다. 아래 이어지는 리스트는 각 노드의 타입에 따른 특이사항을 나열한 것이다.
> Interface Node
Node 인터페이스는 DOM 전체를 통틀어 가장 주요한 데이터타입이다. 문서 트리 상의 한 개 노드를 표현한다. Node 인터페이스를 구현하는 모든 객체들이 자식들을 다루는 메서드를 노출하지만, Node 인터페이스를 구현하는 모든 객체들이 자식을 갖는 것은 아니다. 예를 들어, Text 노드는 자식이 없을 것이고, 해당 노드에 자식을 추가하는 것은 DOMException을 발생시킨다.
특성 nodeName, nodeValue, attributes는 상속받은 특정 인터페이스를 찾을 필요 없이 노드 정보를 얻기 위한 메커니즘으로 포함된 것이다. 이러한 특성들이 특정 nodeType과 확실하게 대응하지 않는 경우 - 예를 들어, Element의 nodeValue 또는 Comment의 attributes), null을 반환한다. 특화된 인터페이스는 관련 정보를 입력 또는 반환하기 위해 추가적인 편의한 메커니즘을 갖고 있을 수 있다.
- 특성
attributes : 이 노드가 Element라면, 이 노드가 가진 특성들을 포함한 NamedNodeMap. 아니면 null 반환.
childNode : 이 노드의 모든 자식들을 포함하는 NodeList. 자식이 없다면, 0개 노드를 포함하는 공백의 NodeList이다. 반환되는 NodeList의 컨텐츠는 "Live"하다. 즉, 노드 객체의 자식들에게 생긴 변화는 반환되는 NodeList 객체에 바로 반영된다. 즉, 노드 상태에 대한 정적인 스냅샷이 아니다. 이것은 getElementsByTagName 메서드에 의해 반환되는 것을 포함한 모든 NodeList에 대해 참이다.
firstChild : 노드의 첫번쨰 자식. 그러한 노드가 없다면, null 반환.
lastChild : 노드의 마지막 자식. 그러한 노드가 없다면, null 반환.
localName : // DOM Level 2에 추가
// XML 전용
namespaceURI : // DOM Level 2에 추가
// XML 전용
nextSibling : 이 노드의 바로 뒤에 존재하는 노드. 그러한 노드가 없다면, null 반환.
nodeName : 노드의 이름으로, nodeType에 따라 다르다.
nodeValue : 노드가 갖는 값으로, nodeType에 따라 다르다.
nodeType : 기반 객체의 타입을 나타내는 코드.
ownerDocument : // DOM Level 2에 추가
이 노드와 관련된 Document 객체. 새 노드를 생성하는 데에 사용되는 Document 객체이기도 하다. 이 노드가 Document와 함께 사용되지 않는 Document 또는 DocumentType 형의 객체라면, 이 값은 null이다.
parentNode : 해당 노드의 부모. Document, DocumentFragment, Attr을 제외한 모든 노드는 부모가 있다. 하지만 노드가 막 생성되어서 트리에 추가되지 않은 상태이거나, 트리에서 제거된 상태라면, 값은 null이다.
prefix : // DOM Level 2에 추가
// XML 전용
previousSibling : 이 노드의 바로 앞에 존재하는 노드. 그러한 노드가 없다면, null 반환.
- 메서드
appendChild : 이 노드의 자식 리스트 맨 뒤에 노드 newChild를 삽입한다. 만약 newChild가 이미 트리에 존재한다면, 우선 제거된다.
cloneNode : 이 노드의 복제본을 반환한다. 보통 노드에 대한 복사 생성자로 이용된다. 복제된 노드는 부모가 없어서 parentNode는 null을 반환한다.
Element를 복사하면 모든 특성과 값, 기본 특성값으로 나타내기 위해 XML 프로세서가 생성한 것까지 모두 복사한다. 하지만 텍스트는 자식인 Text 노드에 포함되지 떄문에, 깊은 복사가 아니라면 텍스트는 복사되지 않는다. 다른 타입의 노드를 복사하는 것은 노드의 단순하게 노드의 복제본으르 반환한다.
hasAttributes : // DOM Level 2에 추가
이 노드가 요소일 때, 특성을 갖고 있는지 여부를 반환한다.
hasChildNodes : 노드가 자식을 갖고 있는지 확인하기 위한 편의상의 메서드이다. 불린 값을 반환한다.
insertBefore : 이미 존재하는 자식 refChild의 앞에 newChild 노드를 삽입한다. refChild가 null이라면, newChild를 자식 리스트 맨 뒤에 삽입.
만약 newChild가 DocumentFragment 객체이면, newChild의 모든 자식들은 동일한 순서로 refChild 앞에 삽입된다. 만약 newChild가 이미 트리 상에 존재한다면, 우선 제거한다.
isSupported : // DOM Level 2에 추가
DOM 구현체가 특정 기능을 구현하는지, 그리고 해당 기능이 이 노드를 통해 지원되는지를 검사한다.
normalize // DOM Level 2에 추가
// XML 전용
replaceChild : 자식 리스트 안에서 자식 노드 oldChlid를 newChild로 교체하고, oldChild 노드를 반환한다. 만약 newChild가 이미 트리 상에 존재한다면, 우선 제거한다.
removeChild : 자식 리스트로부터 자식 노드 oldChild를 제거하고 반환한다.
> Interface NodeList
NodeList 인터페이스는 순서가 있는 노드들의 집합에 대한 추상화를 제공한다. 이때 집합이 구현되는 방식에 대한 규정이나 제약은 포함되지 않는다.
NodeList의 항목들은 0으로 시작하는 숫자 인덱스로 접근할 수 있다.
- 특성
length : 리스트 안의 항목 개수. 자식 노드 첨자의 유효 범위는 0부터 length - 1 까지이다.
- 메서드
item : 집합에서 index번째에 있는 항목을 반환한다. index가 리스트의 노드 개수보다 많거나 같으면 null을 반환한다.
> Interface NamedNodeMap
- 특성
length : 집합 안의 항목 개수. 자식 노드 첨자의 유효 범위는 0부터 length - 1 까지이다.
NamedNodeMap 인터페이스를 구현하는 객체는 이름을 통해 접근할 수 있는 항목의 집합들을 표현하는데 사용된다. NamedNodeMap은 NodeList를 상속하지 않음을 유의하자. NamedNodeMap는 특정한 순서를 갖고 있지 않다. NamedNodeMap를 구현하는 객체에 들어있는 객체들은 서수 첨자로 접근될 수 있지만, 이는 단지 NamedNodeMap의 항목들을 편리하게 열거할 수 있게끔 하기 위함이다. DOM은 안에 들어있는 노드에 대해 순서를 규정하지 않는다.
- 메서드
getNamedItem : 이름으로 특정되는 노드를 반환한다.
getNamedItemNS : // DOM Level 2에 추가
// XML 전용
local name과 네임스페이스 URI를 가진 노드를 반환한다.
item : index번째 항목을 집합에서 반환한다. index가 리스트의 노드 개수보다 많거나 같으면 null을 반환한다.
removeNamedItem : 이름으로 특정되는 노드를 제거한다. 만약 제거되는 노드가 default 값을 갖는 Attr이 경우, 즉시 대체된다.
removeNamedItemNS : //DOM Level 2에 추가
// XML 전용
setNamedItem : nodeName 특성을 사용하여 노드를 추가한다.
노드가 저장될 때에 쓰일 이름을 지정하는 데에 nodeName 특성을 사용하므로, 특정 타입("특별한" string값)을 값으로 갖는 노드가 2개 이상은 저장될 수 없다. 이름이 충돌하기 때문이다.
setNamedItemNS : // DOM Level 2에 추가
// XML 전용
> Interface CharacterData
CharacterData 인터페이스는 DOM 상의 문자 데이터에 접근하는 데에 사용되는 특성과 메서드를 갖도록 Node를 확장한다. 분명하게 말하자면, 이 집합에 대한 인터페이스는 이것을 사용하는 객체가 아닌 여기에서 정의된다. 비록 Text 등의 노드가 이 인터페이스를 상속하기는 하지만, CharacterData에 직접 대응하는 DOM 객체는 없다. 이 인터페이스의 모든 오프셋은 0에서 시작한다.
DOMString 인터페이스에서 설명했듯, DOM의 텍스트 string은 UTF-16으로 표현된다. 즉, 16bit 단위문자의 문자열이다. 앞으로 16bit 단위문자라는 용어를 통해 CharacterData에 대해 인덱싱할 때 한 문자가 16bit로 이루어짐을 나타낼 것이다.
- 특성
data : 이 인터페이스를 구현하는 노드의 문자 데이터. CharacterData 노드에 저장될 수 있는 데이터 양에 있어 DOM 구현체는 임의적 제한을 두지 않는다. 하지만 구현체의 제한은 노드가 갖는 데이터 전체가 단일 DOMString에 들어가지 못한다는 의미일 수 있다. 이런 경우, 사용자는 substringData를 호출하여 데이터를 적절한 사이즈의 조각으로 나누어야 한다.
length : data와 아래의 substringData 메서드를 통해 사용가능한 16bit 문자의 개수. 노드가 비어있을 경우 값으로 0을 가질 수 있다.
- 메서드
appendData : 인자로 받은 string을 노드의 문자 데이터 맨 뒤에 붙인다. 성공하면, 새로운 data는 기존의 data와 인자로 받은 string이 연결된 새로운 string으로 접근할 수 있도록 한다.
deleteData : 노드로부터 일정 범위의 16bit 문자들을 제거한다. 성공하면, data와 length는 변화를 반영한다.
insertData : 주어진 오프셋 위치에 인자로 받은 string을 삽입한다.
replaceData : 주어진 오프셋 위치에서 시작, 인자로 받은 string과 대체한다.
substringData : 노드로부터 일정 범위의 데이터를 추출한다
> Interface Attr
Attr 인터페이스는 Element 객체 안에서 특성을 표현한다. 특성으로서 허용 가능한 값들은 문서 타입 정의에 정의되어있다.
Attr 객체는 Node 인터페이스를 상속받지만, Attr 객체는 실제로는 자신이 묘사하는 요소의 자식 노드가 아니기 때문에, DOM은 Attr 객체를 문서 트리의 일부로 간주하지 않는다. 따라서 Attr 객체를 위한 Node 타입의 특성 parentNode, previousSibling, nextSibling은 모두 null 값을 갖는다. DOM은 특성이란 요소에 포함된 속성이라고 간주하지, 특성과 관련된 요소들로부터 분리된 고유성을 갖는다고 간주하지 않는다. 이것은 어떤 타입 요소가 갖는 디폴트 특성값과 같은 기능을 구현하는 데에 훨씬 효율적이다. 더 나아가, Attr 노드는 DocumentFragment의 직계 자식이 아닐 수도 있다. 하지만 DocumentFragmet 안에 있는 Element 노드와 관련이 있을 수 있다. 요약하면, 사용자와 DOM을 구현하는 사람은 Attr 노드가 Node 인터페이스를 상속받는 다른 객체들과 공유하는 무언가가 있을 수도 있음을 알아야 한다는 것이다. 하지만 이 둘은 꽤 이질적이기도 하다.
특성이 갖는 효과적인 값은 다음의 과정을 통해 결정된다.
1. 만약 해당 특성이 명시적으로 어떤 값을 할당받는다면, 그 값은 해당 특성을 위한 효과적인 값이다.
2. 그것이 아니라 만약 해당 특성을 위한 선언이 있었고 그 선언이 디폴트값을 포함한다면, 그 디폴트값은 해당 특성을 위한 효과적인 값이다.
3. 그것이 아니면, 해당 특성이 직접 명시적으로 추가되기 전까지는 구조 모델 상의 해당 요소에 존재하지 않는다.
XML에서는, 특성값으로 엔티티 참조가 포함될 수 있는데, Attr 노드의 자식 노드는 엔티티 참조가 확장되지 않는 표현 방식을 제공한다. 이 자식 노드는 Text 또는 EntitiyReference 노드이다. 특성 타입이 불명일 수 있기 때문에, 토큰화된 특성값은 없다.
- 특성
name : 해당 특성의 이름을 반환한다.
ownerElement : // DOM Level 2에 추가
이 특성이 포함된 요소를 가리킨다. 만약 다른 요소를 위해 사용되지 않는 특성이라면, null을 갖는다.
specified : 만약 원본 문서에서 해당 특성에 명시적으로 값이 주어졌을 경우, 이 특성은 true를 갖는다. 그렇지 않으면, false를 갖는다. 사용자가 아닌 구현체가 해당 특성에 대해 책임이 있음을 알아두자. 만약 사용자가 특성의 값을 변경하면 - 결국 디폴트값과 같은 값을 갖게 될 지라도 - specified 특성은 자동으로 true로 바뀐다. DTD에서 비롯된 디폴트값을 특성에 부여하기 위해, 사용자는 해당 특성을 제거해야 한다. 그러면 구현체에 의해 specified가 false로 부여되고 디폴트값이 부여된 새로운 특성이 만들어진다.
요약하자면:
- 만약 문서에 의해 특성에 할당된 값이 있다면, specified는 true가 되고, 특성값에는 값이 할당된다.
- 만약 특성에 할당된 값이 없고 디폴트값이 DTD에 있다면, specified는 false이고, 값은 DTD의 디폴트값이 부여된다.
- 만약 특성에 할당된 값이 없고 DTD로부터 비롯된 #IMPLIED 값을 갖고 있다면, 해당 특성은 문서의 구조 모델에 나타나지 않는다.
value : 반환할 때에, 특성의 값은 string으로 반환된다. 문자와 엔티티 참조는 해당하는 값으로 대체된다.
설정에서는, 이것은 파싱되지 않은 string로 이루어진 Text 노드를 생성한다.
> Interface Element
Element 인터페이스는 HTML 및 XML 문서 상의 요소를 표현한다. 요소는 자신과 관련된 특성들을 갖고 있을 수 있다. Element 인터페이스는 Node를 상속받기 때문에, Node 인터페이스의 generic 메서드 getAttributes를 이용하여 해당 요소가 갖는 모든 특성의 집합을 반환받을 수 있다. Element 인터페이스는 Attr 객체를 반환받는 2가지 메서드, 즉 특성 이름으로 받기 또는 특성값으로 받기를 갖고 있다. XML에서는, 특성값이 엔티티 참조를 갖고 있을 수 있기 때문에, 특성값을 표현할 만큼 충분히 복잡한 서브트리인지 검증하기 위해 Attr 객체가 반환되어야 한다. 반면 HTML에서는, 모든 특성이 간단한 string값을 갖고 있기 때문에, 특성값에 접근하는 메서드는 안전하고 편리하게 사용될 수 있다.
알아두기 : DOM Level 2에서는, normalize 메서드는 Node 인터페이스로 이동되고, 그곳으로부터 상속받는다.
- 특성
tagName : 요소의 이름. 예를 들어 아래의 예를 보자.
<elementExample id="demo">
...
</elementExample>
tagName 특성은 값으로 "elementExample"을 갖는다. 이 경우에 대해 XML은 다른 DOM 동작과 마찬가지로 대소문자를 구분한다는 것을 알아두자. HTML DOM의 경우 HTML 요소의 tagName을 반환할 때 기본적으로 대문자 형태로 반환하며, 이는 원본 HTML 문서 상의 대소문자 표기와는 상관없다.
- 메서드
getAttribute : 인자로 특성의 이름을 받고, 특성이 갖는 값을 반환한다.
getAttributeNS : // DOM Level 2에 추가
// XML 전용
getAttributeNode : 인자로 특성의 이름을 받고, 대응하는 Attr 노드를 반환한다.
getAttributeNodeNS : // DOM Level 2에 추가
// XML 전용
getElementsByTagName : 주어진 태그명을 가진 후손 요소들을 모두 담은 NodeList를 반환한다. 이때 순서는 Element 트리에 대해 전위 순회를 했을 경우의 순서이다.
getElementsByTagNameNS : // DOM Level 2에 추가
// XML 전용
hasAttribute : // DOM Level 2에 추가
인자로 특성의 이름을 받고, 해당하는 특성을 이 요소가 갖고 있거나, 디폴트값이 규정되어있을 경우 true를 반환한다. 그렇지 않으면 false를 반환한다.
hasAttributeNS : // DOM Level 2에 추가
// XML 전용
removeAttribute : 인자로 받은 이름을 가진 특성을 제거한다. 만약 제거된 특성에 대해 디폴트값이 존재한다면 즉시 해당 디폴트값으로 교체된다.
removeAttributeNS : // DOM Level 2에 추가
// XML 전용
removeAttributeNode : 특정 특성을 제거한다.
setAttribute : 새 특성을 추가한다. 만약 요소가 해당 이름을 갖는 특성을 이미 갖고 있을 경우, 그 특성값을 매개 변수로 받은 값으로 바꾼다. 이 값은 string이고, 이 값이 새로 부여될 때에는 파싱이 이루어지지 않는다. 따라서 마크업은 리터럴 문자로 취급되어, 새 값이 작성될 때에는 구현체에 의한 적절한 처리가 필요하다.
setAttributeNS : // DOM Level 2에 추가
// XML 전용
setAttributeNode : 새 특성을 추가한다. 만약 요소가 해당 특성을 이미 갖고 있을 경우, 해당 특성 노드를 새 특성 노드로 교체한다.
setAttributeNodeNS : // DOM Level 2에 추가
> Interface Text
Text 인터페이스는 Element 또는 Attr의 텍스트 컨텐츠를 표현한다. XML에서는 이를 문자 데이터라는 용어로 부른다. 만약 요소 컨텐츠 내부에 마크업이 없다면, 텍스트는 요소의 유일한 자식이자, Text 인터페이스를 구현하는 단일 객체 안에 포함된다. 마크업이 있다면, Element와 Text 노드의 리스트로 파싱되면서 해당 요소의 자식이 된다.
문서가 DOM을 통해 처리된 직후에는 각 텍스트 블록에 대해 단 하나의 Text 노드만을 갖는다. 사용자는 마크업을 거스르지 않고 주어진 요소의 내용을 표현할 수 있는 인접한 Text 노드를 생성한다. 하지만 사용자가 XML과 HTML 상에서 각 노드들 사이에 분리를 표현할 방법이 없기 때문에, DOM 편집 세션에 있어 특정 방향을 고집할 수는 없다는 것을 알고 있어야 한다. normarlize() 메서드를 Element에 사용하면 이처럼 인접한 Text 객체들을 한 블록 텍스트로 이루어진 단일 노드로 합칠 수 있다. 이것은 특정 문서 구조에 의존하는 동작 - XPointers를 이용한 탐색 등 - 을 수행하기 전에 권장된다.
- 메서드
splitText : Text 노드를 지정한 오프셋을 기준으로 두개 노드로 나누고, 두 노드는 트리 상에서 형제로 유지한다.
> Interface Comment
코멘트의 내용을 표현한다. 예를 들어 '<!--'와 '-->' 사이에 존재하는 모든 문자들을 표현한다. 비록 일부 HTML 도구는 완전하게 SGML 코멘트 구조를 구현하지만, 이것이 XML과 HTML의 코멘트를 정의한다는 것을 기억하자.
* 각 인터페이스의 경우, IDL 정의를 비롯한 자세한 내용이 생략되어있으며, 특성과 메서드만 목록화하였습니다. 자세한 구현 내용은 원문을 검색해주세요.
* 혹-시나, 상업적 용도로 사용하지 말아주세요.
문서 객체 모델이란 무엇인가?
도입
문서 객체 모델(DOM)이란 HTML과 XML 문서를 위한 응용 프로그램 개발 인터페이스(API)이다. DOM은 문서의 논리적 구조, 문서가 접근되고 조작되는 방식을 정의한다. DOM 기술에서, 용어 "문서"는 넓은 의미로 쓰인다. 점점, XML은 여러 시스템에서 보관되는 다양한 종류의 정보를 표현하는 하나의 방식으로 사용되고 있다. 또한 대부분의 XML은 전통적으로 문서라기보다는 데이터로서 여겨져왔다. 그럼에도 불구하고, XML은 문서를 통해 데이터를 제시하고, DOM은 이러한 데이터를 다루기 위해 사용된다.
DOM을 통해 개발자는 문서를 구축하고, 그 구조를 다룰 수 있게 되며, 요소나 컨텐츠를 더하거나 수정, 삭제할 수 있다. DOM을 통해 HTML 및 XML 문서에서 발견된 무엇이든지 접근하거나, 수정하거나, 삭제하거나, 새로 추가할 수 있는 것이다. 다만 몇 가지 예외는 있다 - 특히, XML의 내/외부 하위셋에 대한 DOM 인터페이스는 아직 정해지지 않았다.
W3C 명세에 있어 DOM을 위한 중요한 목표 중 하나는 다양한 환경과 응용 프로그램에서 사용될 수 있는 표준 프로그래밍 인터페이스를 제공하는 것이다. DOM은 어떤 프로그래밍 언어와도 사용될 수 있도록 디자인되었다. 정확하면서도 특정 언어에 종속되지 않은 DOM 인터페이스 명세를 제공하기 위해, 우리는 CORBA 2.2 명세에서 정의된 바와 같이 OMG IDL을 이용하여 명세를 정의하기로 결정하였다. OMG IDL 명세에 더하여, 우리는 Java와 ECMAScript에 대한 언어 바인딩도 제공한다.
알아두기: OMG IDL은 오로지 인터페이스 명세에서 특정 언어에 종속되지 않고, 중립적인 구현을 하는 데에만 사용된다. 기타 다양한 IDL 역시 사용될 수 있다. 보통 IDL은 특정 컴퓨팅 환경을 대상으로 디자인된다. DOM은 어떤 컴퓨팅 환경에서도 구현될 수 있고, 특정 IDL에 연관된 객체 바인딩 런타임을 요구하지 않는다.
문서 객체 모델이란 무엇인가
DOM은 문서를 위한 프로그래밍 API이다. DOM은 모델링하는 문서의 구조를 닮앗다. 예를 들어, HTML 문서에서 가져온 아래 표를 보자.<TABLE>
<TBODY>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</TBODY>
</TABLE>
DOM은 이 표를 아래와 같이 표현한다.
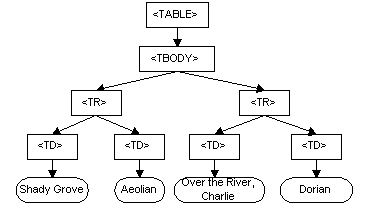
DOM에서는, 문서는 트리와 유사한 모습의 논리적 구조를 갖는다. 더 정확하게 말하자면, 한 개 이상의 트리를 갖고 있는 "Forest" 자료 구조와 닮았다. 하지만 DOM은 문서가 트리 또는 포레스트로 구현되어야 한다고 규정하고 있지 않으며, 객체 간의 관계가 어떻게 구현되어야하는지를 규정하고 있지도 않다. DOM은 어떤 편리한 방식으로 구현되어도 상관없는 논리적 모델이다. 이 정의에서 우리는 구조 모델이라는 용어를 사용하여, 트리와 닮은 모양으로 문서를 표현하는 것을 설명한다. DOM 구조 모델의 한 가지 중요한 속성은 구조적 동형률(Structural Isomorphism)이다. 만약 두 DOM 구현이 동일한 문서를 표현하고자 한다면, 두 구현 결과물은 동일한 구조 모델을 생성할 것이며, 두 모델은 XML 정보 집합에 의거하여 정확하게 동일한 객체들과 관계들로 이루어질 것이다.
알아두기 : DOM을 구축하는 데에 사용한 파서에 따라 다양한 변형이 존재한다. 예를 들어, 파서가 삭제할 경우 DOM은 요소 내의 공백을 포함하지 않을 수도 있다.
"문서 객체 모델"은 전통적인 객체 지향 디자인 측면에서 볼 때 "객체 모델"이기 때문에 이와 같은 이름이 지어졌다. 여기서 문서는 객체를 이용하여 모델링되며, 이 모델은 문서의 구조뿐만 아니라, 문서와 문서 안의 요소들의 행동을 모두 아우른다. 즉, 위의 도형에서 노드들은 자료구조를 나타내는 것이 아니라, 제각기 기능과 식별성을 지닌 객체를 나타낸다. 객체 모델로서, DOM은 아래와 같은 사항들을 알려준다.
- 문서를 나타내고 조작하는 데에 사용되는 인터페이스와 객체
- 이러한 인터페이스와 객체에 대한 의미론 / 행위와 속성 포함
- 이러한 인터페이스와 객체들 간의 관계와 공동의 결과
전통적으로 SGML 문서의 구조는 객체 모델이 아닌 추상 데이터 모델로 표현되었다. 추상 데이터 모델에서는, 모델은 데이터 중심으로 형성된다. 객체 지향 프로그래밍 언어에서는, 데이터는 데이터를 캡슐화하여 숨기는 객체 내부에 들어 있어서 직접적인 외부 조작으로부터 보호된다. 이러한 객체들과 관련된 함수들은 객체들이 조작되는 방식을 결정하며, 이 또한 객체 모델의 일부이다.
문서 객체 모델이란 이런 것이 아니다
본 섹션에서는 다른 시스템과 구별하는 것을 통해 DOM에 대한 정확한 이해를 제공한다.
- DOM은 이진법으로 작성된 명세가 아니다. 동일한 언어로 작성된 DOM 프로그램은 이에 호환되는 다른 플랫폼에서도 소스 코드로서 작동하겠지만, DOM은 어떠한 형태의 이진 연산도 정의하고 있지 않다.
- DOM은 XML 또는 HTML이 객체를 사용하게끔 하는 것이 아니다. 객체들이 XML에서 표현되는 방식을 규정하는 대신, DOM은 XML과 HTML 문서가 객체로서 어떻게 표현되는지를 규정하여 객체 지향 프로그램에서 사용될 수 있도록 한다.
- DOM은 자료구조가 아니라, 인터페이스를 규정하는 객체 모델이다. 비록 본 문서에서 부모/자식 관계를 나타내는 모형을 사용하고 있기는 하지만, 이것은 프로그래밍 인터페이스가 규정하는 논리적 관계이며, 특정 내부 자료구조를 표현한 것이 아니다.
- DOM은 XML 또는 HTML의 "진정한 내무 의미론"을 규정하지 않는다. XML과 HTML의 언어 의미론은 해당 언어들에 대한 W3C 권고안에서 규정된다. DOM은 그러한 의미론들을 모두 수용할 수 있도록 디자인된 프로그래밍 모델이다. DOM은 XML과 HTML 문서를 작성하는 방법에 대해 상관하지 않는다. 해당 언어로 작성된 어떤 문서든 DOM을 통해 표현될 수 있다.
- 비록 이름이 이렇긴 하지만, DOM은 구성 요소 객체 모델(Component Object Model)이 경쟁 상대가 아니다. COM은 CORBA와 마찬가지로 인터페이스와 객체를 규정하는 언어 독립적 방법이다. DOM은 HTML 및 XML 문서를 다룰 수 있도록 디자인된 인터페이스와 객체의 집합이다. DOM은 COM과 CORBA와 같은 언어 독립적 시스템을 이용하여 구현될 수 있다. 또한 Java, ECMAScript와 같은 특정 언어에 종속된 구현도 가능하다.
문서 객체 모델은 어디에서 비롯되었나
DOM은 JavaScript 스크립트와 Java 프로그램이 웹 브라우저들 간에 포팅하고자 하는 의도에서 비롯되었다. "동적 HTML"은 DOM의 직계 조상이며, 처음에는 브라우저 차원의 발상이었다. 하지만 W3C에 DOM 작업 그룹이 형성되고 난 뒤, 이 그룹은 HTML 및 XML 에디터 또는 문서 저장소 등을 포함하는 다른 영역의 판매 회사들도 참여하게 되었다. 이 판매사들 중 몇몇은 XML이 개발되기 이전에 SGML을 이용하기도 했다. 그 결과 DOM은 SGML 계열과 HyTime 표준의 영향을 받게 되었다. 일부 판매사들은 SGML/XML 에디터 또는 문서 저장소에 API를 제공하기 위하여 자사 고유의 객체 모델을 개발하기도 하였는데, 이 또한 DOM에 영향을 끼쳤다.
엔티티와 DOM Core
기본적인 DOM 인터페이스에는 엔티티를 나타내는 객체가 존재하지 않는다. 숫자형 문자 참조. HTML과 XML에서 미리 정의된 엔티티에 대한 참조는 엔티티의 교체를 메꾸는 단일 문자로 대체된다. 예를 들어 아래의 코드를 보자.
<p>This is a dog & a cat</p>
"&"는 문자 "&"로 대체되며, P 요소 내의 텍스트는 단일한 연속 문자열을 형성한다. 숫자형 문자 참조와 미리 정의된 엔티티는 HTML 상의 CDATA 섹션, SCRIPT 또는 STYLE 요소에서는 인식되지 않기 떄문에, 본래 의도로 생각되는 단일 문자들로 대체되지 않는다. 예시 코드가 CDATA 섹션으로 둘러쌓여있다면, "&"는 대체되지 않을 것이고, <p>는 시작 태그로 인식되지 않을 것이다. 내부든 외부든 일반적인 엔티티에 대한 표현은 Level 1 명세의 XML 인터페이스 상에 정의되어 있다.
알아두기: 문서의 DOM 표현이 XML 또는 HTML 텍스트 문자열이라면, 응용 프로그램은 텍스트 데이터 내의 각 문자를 검사하여 숫자 참조 또는 미리 정의된 엔티티로 교체할 필요가 있는지 파악해야 한다. 이에 실패할 경우 HTML 또는 XML를 제대로 출력할 수 없게 된다. 또한, 인코딩에 존재하지 않는 문자가 마크업 또는 CDATA 섹션에 존재할 경우, ISO 10646을 충족하지 않는 문자 인코딩("charset")으로 문자열을 만드는 작업은 실패할 수도 있다는 점을 구현할 때 인지하고 있어야 한다.
준수
본 섹션은 DOM Level 2 준수 정도에 대해 설명한다. DOM Level 2는 14개 모듈로 구성되어있다. DOM Level 2 또는 DOM Level 2 모듈을 준수하는 것이 가능하다.
구현체가 DOM Level 2를 준수한다고 함은, 본 문서에서 규정하는 Core 모듈을 지원하는 것이다. 또한 구현체가 DOM Level 2를 준수한다고 함은 모듈을 위한 인터페이스, 그리고 모듈과 관련된 의미론을 위한 인터페이스를 지원하는 것이다.
아래의 리스트는 DOM Level 2 모듈과 그 모듈이 사용하는 기능들이다. 기능들은 대소문자를 구분하지 않는다.
- Core module
- XML module
- HTML module
- Views module
- Style Sheets module
- CSS module
- CSS2 module
- Events module
- UI Events module
- Mutation module
- HTML Events module
- Range module
- Traversal module
DOM 구현체는 DOMImplementation 인터페이스의 hasFeature(feature, version) 메서드에 대해 대응하는 기능이 모듈을 구현하고 있지 않다면 true를 반환해선 안 된다. DOM Level 2.0에 속한 기능들에 대해 사용되는 숫자 version은 "2.0"이다.
DOM 인터페이스와 DOM 구현
DOM은 XML 및 HTML 문서를 다루는 데에 어떤 인터페이스가 사용되는지 규정한다. 이러한 인터페이스는 마치 C++의 "추상 기반 클래스"와 같이 추상화이다. 즉, 어떤 문서에 대한 응용 프로그램의 내부 표현에 접근하고 조작하는 수단이다. 인터페이스는 구체적인 구현을 암시하고 있지 않다. 각 DOM 응용 프로그램은 문서를 어떤 방식으로든 표현할 수 있으며, 본 명세에 제시된 인터페이스가 지원되기만 하면 된다. 일부 DOM 구현물은 DOM 명세가 만들어지기도 전에 작성된 소프트웨어에 접근하기 위한 DOM 인터페이스를 사용하는 구닥다리 프로그램이다. 따라서 DOM은 구현 의존성을 피하도록 디자인되었다. 아래의 사항은 특히 강조하는 부분이다.
- Attributes defined in the IDL do not imply concrete objects which must have specific data members - in the language bindings, they are translated to a pair of get()/set() functions, not to a data member. (Read-only functions have only a get() function in the language bindings).
- DOM 응용 프로그램은 본 명세에는 없는 추가적인 인터페이스와 객체를 제공할 수 있으며 여전히 DOM 표준을 준수하는 것이다.
- 인터페이스를 규정하고 실제 생성되는 객체를 규정하지 않기 때문에, DOM은 구현을 위하여 어떤 생성자를 호출할 것인지 알지 못한다. 보통 DOM 사용자는 createXXX() 메서드를 Document 클래스에 대해 사용하여 문서 구조를 생성하고, DOM 구현체는 해당 구조에 대한 내부 표현을 createXXX() 함수 코드로 작성한다.
Level 1 인터페이스는 Level 1과 Level 2 기능을 모두 지원하기 위해 확장되었다.
Java 또는 ECMAScript를 제외한 나머지 언어를 위한 DOM 구현체는 해당 언어와 런타임을 위해 자연스럽고 적절한 바인딩을 선택해야한다. 예를 들어, 일부 시스템은 Document를 상속받고 새 메서드와 특성을 포함하는 Document2 클래스를 생성해야 할 수도 있다.
DOM Level 2는 멀티스레딩 메커니즘을 정의하지 않는다.
1. 문서 객체 모델 COre
1.1 DOM Core 인터페이스의 개관
본 섹션에서는 문서 객체에 접근하고 조작하기 위한 최소한도의 객체와 인터페이스 집합을 정의한다. 본 섹션에서 정의된 기능성(핵심 기능성)은 소프트웨어 개발자과 웹 스크립트 개발자들이 표준을 준수하는 제품 속의 HTML과 XML 코드를 파싱한 결과물에 접근하고 조작하는 데에 충분할 것이다. The DOM Core API also allows population of a Document object using only DOM API calls; Document를 로드하고 저장하는 방법은 DOM API를 구현하는 제품에게 맡긴다.
1.1.1 DOM 구조 모델
DOM은 문서를 Node 객체의 계층 구조로서 제시하며, 여기서 Node 객체는 다른 특화된 인터페이스를 구현하기도 하는 객체이다. 일부 타입의 노드는 다양한 타입의 또다른 자식 노드를 가지며, 또 어떤 노드는 문서 구조 상에서 다른 자식을 가질 수 없는 리프 노드이다. 노드의 타입과, 각 타입들이 가질 수 있는 자식의 타입들은 아래와 같다.
- Document : Element(Maximum of one), ProcessingInstruction, Comment, DocumentType
- DocumentFragment : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- DocumentType : 자식 없음
- EntityReference : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- Element : Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference
- Attr : Text, EntityReference
- ProcessingInstruction : 자식 없음
- Comment : 자식 없음
- Text : 자식 없음
- CDATASection : 자식 없음
- Entity : Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
- Notation : 자식 없음
DOM은 NodeList 인터페이스를 규정하여 Node로 이루어진 순서가 있는 리스트를 처리할 수 있다. 이러한 리스트의 예로는 Node의 자식들, Element.getElementsByTagName 메서드에 의해 반환되는 요소들이 있다. 또한 DOM은 NamedNodeMap 인터페이스를 규정하여 순서가 없는 Node들의 집합을 처리할 수 있다. 이 집합의 내부 항목들은 각각이 갖고 있는 name 특성을 통해 참조될 수 있다. 이러한 집합의 예로는 Element의 attribute들이 있다. DOM의 NodeList와 NamedNodeMap은 "Live 상태"이다. 즉, 기반이 되는 문서 구조에 대한 변화가 관련 NodeList와 NamedNodeMap에 반영된다는 것이다. 예를 들어, DOM 사용자가 Element의 자식 객체로 이루어진 NodeList 객체를 얻고, 최종적으로 해당 요소에 추가적인 자식을 추가하거나, 수정 또는 제거하였다고 하자. 이떄 이러한 변경점은 사용자의 추가적인 작업 없이 자동으로 NodeList에 반영된다는 것이다. 같은 방식으로, 어떤 Node에 대한 변경점은 Node를 가리키는 모든 참조에 반영된다.
1.1.2 메모리 관리
명세를 통해 정의된 대부분의 API들은 클래스가 아닌 인터페이스이다. 즉 실제 구현을 할 경우, 미리 규정된 이름과 정해진 작동 방식을 메서드와 함께 노출시킬 뿐이지, 해당 인터페이스와 직접 대응하는 클래스를 실제로 구현하는 것이 아니다. 이를 통해 DOM API는 마치 베니어 합판처럼, 레거시 응용 프로그램이 갖는 자료구조를 유지하면서 그 위에 얇게 구현될 수 있도록 해준다. 혹은 다른 클래스 구조를 지닌 새로운 프로그램 위에 얇게 구현될 수 있도록 해준다. 이것은 또한 Java 또는 C++의 경우와는 달리, 기존의 생성자로는 DOM 객체를 생성할 수 없다는 것이다. 왜냐하면 기반 객체를 생성할 (응용 프로그램의) 생성자는 DOM 인터페이스와는 아무 관련이 없을 것이기 때문이다. 객체 지향 디자인에서 이에 대한 전통적인 해결책은 다양한 인터페이스를 구현하는 객체 인스턴스를 만들 수 있는 factory메서드를 정의하는 것이다. 어떤 인터페이스 'X'를 구현하는 객체는 Document 인터페이스의 "CreateX()" 메서드로 생성한다. 이것은 모든 DOM 객체는 특정 문서의 문맥 위에서 존재하기 때문이다.
DOM Level 2 API는 DOMImplementation 또는 Document 객체를 만드는 표준적 방법을 규정하지 않는다. 실제 DOM 구현체는 이러한 인터페이스를 구현하는 독점적 방법을 제공해야 한다. 그래야 다른 객체들이 Document의 Create 메서드를 통해 구축될 수 있다.
Core DOM API는 다양한 언어에 호환되도록 디자인되었으며, 여기에는 평이한 난이도의 스크립트 언어와 전문 개발자가 사용하는 고난이도 언어를 포함한다. 즉, DOM API는 다양한 메모리 관리 철학에 상관없이 작동해야 한다. 이를테면 생성자를 명시적으로 제공하지만 자동 카비지 콜렉션 메커니즘을 제공하여 메모리 관리를 사용자에게 전혀 노출하지 않는 Java같은 언어 플랫폼부터, 개발자로 하여금 명시적으로 객체 메모리를 할당하고 사용 상황을 추적하여 명시적으로 해제까지 해야하는 C++과 같은 언어까지 다양하게 대응해야 한다. 다양한 플랫폼에 대해 일관성있는 API를 보장하기 위해, DOM은 메모리 관리 문제를 일절 다루지 않고, 구현 단계에 맡긴다. DOM 작업 그룹이 고안한 언어 바인딩 중 그 어떤 것도 메모리 관리 메서드를 요구하지 않는다. 하지만 다른 언어를 위한 DOM 바인딩은 이에 관한 지원을 할 것이다. 이러한 확장은 DOM API를 특정 언어로 포팅하는 사람들의 책임이며, DOM 작업 그룹이 다룰 사안이 아니다.
1.1.3 네이밍 컨벤션
특성과 메서드 이름이 짧고, 정보를 전달하고, 내부적으로 일관성을 유지하며, 비슷한 API를 사용하는 사용자에게 친숙하다면 좋겠지만, 한편으로는 DOM 구현체가 지원하는 레거시 API의 이름과 충돌해서는 안 된다. 더 나아가 OMG IDL과 ECMAScript는 이름이 겹치지 않으면서 친숙하게 짧게 만들기에는, 다양한 네임스페이스들 사이에서 명확성을 부여하기가 어렵다. 따라서 다양한 환경을 아우르며 유일성을 지니기 위해, DOM의 명칭들은 길고 서술성이 짙은 경향이 있다.
DOM 작업 그룹은 다양한 용어를 사용하는 데에 있어 내부적으로 일관되고자 노력해왔다. 비록 다른 API에서는 쉽게 보기 힘든 구분법이지만 말이다. 예를 들어, "remove"라는 이름은 메서드가 구조적 모델에 변화를 가할 때에 사용하고, "delete"는 구조적 모델 차원에서 메서드가 무언가를 제거할 때에 사용한다. Delete되는 것은 복구할 수 없다. Remove되는 것은 이치에 맞다면 다시 복구할 수 있다.
1.1.4 상속 vs API에 대한 평평한 시점
DOM Core API는 XML/HTML문서에 왠지 다른 2개의 인터페이스 집합을 제공한다. 상속 계층구조를 통한 "객체 지향적" 접근, 그리고 형변환이 없이 노드 인터페이스 또는 쿼리 인터페이스 호출를 사용하여 조작할 수 있도록 하는 "단순화된" 시점이다. 이 동작들은 Java와 COM에서는 꽤 고비용 동작이며, DOM은 성능이 중요한 환경에서 사용될 수도 있기 때문에, 중요한 기능을 동작하는 데에 있어 노드 인터페이스만을 이용하게끔 한다. DOM을 대하는 데에 있어 "모든 것은 노드이다"라는 접근보다는 상속 구조를 더 이해하기 쉽게 느낄 것이기 때문에, 객체지향 API를 선호하는 사람들을 위해 고레벨 인터페이스를 제공한다.
이것은 API에 반복이 많다는 뜻이다. DOM 작업 그룹은 "상속" 접근을 API를 대하는 주된 관점으로 삼고, Node에 대한 모든 기능들은 "추가적인" 기능으로 간주한다. But that does not eliminate the need for methods on other interfaces that an object-oriented analysis would dictate. 물론, 객체 지향적 분석이 Node 인터페이스에 존재하는 것과 겹치는 특성 또는 메서드를 낳는다면, 그것을 두고 반복이라고 말하지는 않는다. 따라서, Node 인터페이스에 nodeName이라는 흔한 특성이 있다고 하더라도, Element 인터페이스에도 여전히 tagName이라는 특성이 존재한다. 이 두 특성은 같은 값을 갖겠지만, DOM 작업 그룹은 DOM API가 지원해야 하는 여러 상황을 모두 고려했을 때 두 가지 상황 모두를 지원하는 것이 바람직하다고 생각했다.
1.1.5 DOMString 타입
상호동작성을 보장하기 위해, DOM은 DOMString이라는 타입을 아래와 같이 정의한다.
- DOMString은 16bit 크기의 문자로 이루어진 문자열로, IDL로 표현하면 다음과 같다.
typedef sequence<unsigned short> DOMString;
- 응용 프로그램은 DOMString을 UTF-16을 이용하여 인코딩해야한다. UTF-16은 실제 산업 현장에서 널리 쓰이고 있기 때문에 채택되었다. HTML, XML은 모두 문서 문자 세트가 UCS-4를 기반으로 두고 있다. 따라서 단일 숫자형 문자 참조는 때로는 DOMString에서 2개 칸을 차지하기도 한다.
알아두기: DOM은 string 타입의 이름을 DOMString으로 정의하고 있지만, 바인딩은 다른 이름을 사용할 수도 있다.
1.1.6 DOMTimeStemp 타입 // DOM Level 2에 추가
상호동작성을 보장하기 위해, DOM은 DOMTimeStamp라는 타입을 아래와 같이 정의한다.
- DOMTimeStamp는 밀리초를 숫자로 표현한다.
알아두기 : DOM은 DOMTimeStamp 타입을 사용하긴 하지만, 바인딩은 다른 타입을 사용할 수 있다. Java의 예를 들면, DOMTimeStamp는 long 타입으로 바인드된다. ECMAScript의 경우, TimeStamp는 Data 타입으로 바인드되는데, 왜냐하면 integer 타입의 범위가 너무 작기 때문이다.
1.1.7 DOM에서 string 비교
DOM은 문장 매칭을 담고 있는 인터페이스를 많이 갖고 있다. HTML 프로세서는 보통 대문자 일반화를 가정하여 요소 등의 이름을 다룬다. 반면 XML은 명시적으로 대소문자를 구분한다. DOM에 있어 string 매칭은 16bit 크기인 개별 문자 코드 하나하나에 대하여 이루어진다. 이처럼 DOM은 DOM 구조가 구축되기 전에 프로세서에서 어떤 형태의 일반화가 이루어질 것으로 가정한다.
이것은 어떤 일반화가 발생하는지의 문제를 제기하게 된다. W3C I18N 그룹은 DOM을 구현하는 응용 프로그램에 대해 어떤 일반화가 필요한지를 규정하는 과정을 수행하고 있다.
1.1.8 XML 네임스페이스 // DOM Level 2에 추가
DOM Level 2는 DOM Level 1의 여러 인터페이스들을 보강하여 XML 네임스페이스를 지원한다. 이를 통해 네임스페이스와 관련된 요소와 특성들을 생성하고 조작할 수 있다.
DOM과 관련한 한,
<-------------미완성--------------->
1.2 근본 인터페이스
본 섹션에 포함된 인터페이스는 근본으로 간주되며, 표준을 준수하는 모든 DOM 구현체는 HTML DOM구현과 더불어 이를 모두 구현해야 한다.
> Exception DOMException
DOM 동작은 오직 "예외적" 상황에서 - 예를 들어 동작을 수행하는 것이 불가능할 경우(논리적 이유, 데이터 소실, 구현이 불안정함 등) - 만 예외를 던진다. 보통 DOM 메서드는 본래의 처리 상황 속에서 특정 오류값을 반환한다. 예를 들면 NodeList를 사용하고 있을 때 out-of-bound 오류를 반환하는 것이다.
구현체는 다른 상황에는 다른 예외를 던질 것이다. 예를 들어 null 인자가 전달되었을 경우, 구현체는 구현 의존적인 예외를 던질 것이다.
어떤 언어나 객체 시스템은 예외라는 개념을 지원하지 않는다. 그러한 시스템에 대해서는, 네이티브 오류 보고 메커니즘을 사용하여 오류 조건을 가리켜야 한다. 예를 들어 어떤 바인딩의 경우, 메서드는 대응하는 메서드 설명에 존재하는 것과 유사한 오류 코드를 반환한다.
> Interface DOMImplementation
DOMImplementation 인터페이스는 DOM의 특정 인스턴스에 독립적인 동작을 위한 메서드들을 제공한다.
DOM Level 1에서는 document 인스턴스를 생성하는 방법을 규정하지 않는다. 따라서 document 생성은 구현체를 위한 작동이다. 차후의 DOM Level 정의에서 document를 직접 생성하는 메서드를 제공할 것으로 기대된다.
- 메서드
createDocument : // DOM Level 2에 추가
// XML 전용
createDocumentType : // DOM Level 2에 추가
// XML 전용
hasFeature : DOM 구현체가 특정 기능을 구현하고 있는지 검사
> Interface DocumentFragment
DocumentFragment는 "가벼운" 또는 "최소한의" Document 객체이다. 문서 트리의 일부만 추출하거나, 문서의 일부분을 생성하는 것은 종종 필요한 작업이다. 일부분만 이동하여 문서를 재배열하거나 자르기의 사용자 명령을 구현한다고 상상해보자. 이러한 일부분을 포함하는 객체를 갖는 것은 바람직하며 이러한 목적을 위해 Node를 사용하는 것은 자연스럽다. Document 객체가 이러한 역할을 충족할 수 있기는 하지만, Document 객체는 기반하는 구현제에 따라 잠재적으로 아주 무거운 객체가 될 수 있다. 아주 가벼운 객체가 필요한 것이다. DocumentFragment는 그러한 객체이다.
더 나아가, 다양한 동작 - 예를 들어, 다른 노드(A)에 자식으로서 노드를 삽입하기 - 은 DocumentFragment 객체를 인자로서 사용할 수 있다. 이 통해 DocumentFragment의 자식 노드들이 모두 이 노드(A)의 자식 리스트로 이동될 수 있다.
DocumentFragment 노드의 자식들은 0개 이상의 노드로, 문서 구조를 정의하는 어떤 서브트리의 루트일 수 있다. DocumentFragment 노드는 잘 정리된 XML 문서일 필요는 없다. 예를 들어, DocumentFragment는 단 하나의 자식만 가지며, 그 자식 노드는 Text 노드일 수 있다. 이러한 구조 모델은 HTML 문서와 XML 문서 모두 대응되지 않는다.
DocumentFragment가 Document(또는 자식을 받을 수 있는 다른 노드)에 삽입되면 DocumentFragment의 자식들은 해당 Node로 삽입되지만, DocumentFragment 자신은 삽입되지 않는다. 이것은 DOM 사용자가 형제 노드를 만들고 싶을 때 유용하게 사용할 수 있다. DocuentFragment는 노드들의 부모로서 작용하며, 사용자는 insertBefore(), appendChild() 등 Node 인터페이스의 표준 메서드들을 사용할 수 있다.
> Interface Document
Document 인터페이스는 HTML 또는 XML 문서 전체를 표현한다. 개념적으로 이것은 문서 트리의 루트에 해당하며, 문서의 데이터에 대한 가장 빠른 접근을 제공한다.
element, text node, comment, processing instruction 등은 Document의 문맥을 벗어나서 존재할 수 없기 때문에, Document 인터페이스는 이러한 객체들을 생성하는 데에 필요한 factory 메서드를 갖고 있다. 생성된 Node 객체는 ownerDocument 특성을 가지며, 이를 통해 그들이 생성된 문맥 안에서 Document와 연결된다.
- 특성
doctype : 해당 문서와 관련된 문서 타입 선언. 문서 타입 선언이 없다면 null을 반환한다. DOM Level 1은 문서 타입 선언 변경을 지원하지 않으므로, docType은 변경될 수 없다.
implementation : 해당 문서를 다루는 DOMImplementation 객체. DOM 응용 프로그램은 다양한 구현체로부터 객체를 제공받아 사용할 것이다.
documentElement : 문서의 루트 요소이자 Document의 자식 노드로 직접 접근을 허용하는 편의 상의 특성. HTML 문서라면, 이것은 tagName으로 "HTML"을 갖는 요소이다.
- 메서드
createElement : 정의된 타입의 요소를 생성한다. 반환된 인스턴스는 Element 인터페이스를 구현한 것으로, 따라서 반환된 객체에는 특성이 직접 지정될 수 있다.
또한 디폴트값이 정해진 특성이 있다면, 이를 표현하는 Attr 노드가 자동으로 생성되고 요소에 추가된다.
한정자와 네임스페이스 URI로 요소를 만들고 싶다면, createElementNS 메서드를 사용하자.
createElementNS : // XML 전용
createDocumentFragment : 공백인 DocumentFragment 객체를 생성한다.
createTextNode : 주어진 string을 받아 텍스트 노드를 생성한다.
createComment : 주어진 string을 받아 코멘트 노드를 생성한다.
createCDATASection : 주어진 string을 받아 CDATASection 노드를 만든다. // HTML 미지원
createProcessingInstruction : 주어진 이름과 데이터를 받아 ProcessingInstruction 노드를 생성한다. // HTML 미지원
createAttribute : 주어진 이름의 Attr을 생성한다. Attr 인스턴스는 setAttribute 메서드를 이용하여 요소에 적용될 수 있다.
createAttributeNS : // DOM Level 2에 추가
// XML 전용
createEntityReference : EntityReference 객체를 생성한다 // HTML 미지원
getElementById : // DOM Level 2에 추가
인자로 주어진 elementID를 가진 요소를 반환한다. 만약 그러한 요소가 존재하지 않으면 null을 반환한다. 동일 ID를 가진 요소가 1개 이상일 때의 작동을 정의하지 않는다.
알아두기 : DOM 구현체는 어떤 특성이 ID 타입인지에 대한 정보를 갖고 있어야 한다. 따로 정의된 것이 아니라면, "ID"라는 이름을 가진 특성은 ID 타입이 아니다. 특성이 ID 타입인지 여부를 구현체가 알지 못하면 null을 반환할 것으로 예상한다.
getElementsByTagName : 주어진 태그명과 일치하는 요소들로 이루어진 NodeList를 반환한다. 이때 순서는 Document 트리에 대해 전위 순회를 했을 경우의 순서이다.
getElementsByTagNameNS : // DOM Level 2에 추가
주어진 local name과 네임스페이스 URI를 가진 모든 요소로 이루어진 NodeList를 반환한다. 이때 순서는 Document 트리에 대해 전위 순회를 했을 경우의 순서이다.
importNode : // DOM Level 2에 추가
다른 문서에서 해당 문서로 노드를 가져온다. 반환되는 노드는 부모가 없다. 즉, parentNode가 null을 갖는다. 다른 문서에 있는 원본 노드는 변형되거나 제거되는 것이 아니라, 본 메서드를 통해 원본 노드의 복제본을 생성하는 것이다.
모든 노드에 대해, 노드를 import하는 동작은 import를 수행하는 문서가 소유하게 될 새로운 노드 객체를 생성하게 된다. 이때 원본 노드가 갖고 있는 특성들, nodeName, nodeType, 네임스페이스와 관련된 특성들 - prefix, localName, namespaceURI 등 - 을 모두 동일하게 가져오게 된다. Node 인터페이스의 cloneNode과 마찬가지로, 원본 노드는 변경되지 않는다.
추가적인 정보는 nodeType에 따라 적절하게 복사되며, 이는 원본 문서에 있던 XML 또는 HTML의 일부분이 다른 문서로 복사되었을 때 예상되는 동작을 모방하여 구현하기 위함이다. XML의 경우에 두 문서가 서로 다른 DTD를 가질 수 있음을 인식하는 것이다. 아래 이어지는 리스트는 각 노드의 타입에 따른 특이사항을 나열한 것이다.
> Interface Node
Node 인터페이스는 DOM 전체를 통틀어 가장 주요한 데이터타입이다. 문서 트리 상의 한 개 노드를 표현한다. Node 인터페이스를 구현하는 모든 객체들이 자식들을 다루는 메서드를 노출하지만, Node 인터페이스를 구현하는 모든 객체들이 자식을 갖는 것은 아니다. 예를 들어, Text 노드는 자식이 없을 것이고, 해당 노드에 자식을 추가하는 것은 DOMException을 발생시킨다.
특성 nodeName, nodeValue, attributes는 상속받은 특정 인터페이스를 찾을 필요 없이 노드 정보를 얻기 위한 메커니즘으로 포함된 것이다. 이러한 특성들이 특정 nodeType과 확실하게 대응하지 않는 경우 - 예를 들어, Element의 nodeValue 또는 Comment의 attributes), null을 반환한다. 특화된 인터페이스는 관련 정보를 입력 또는 반환하기 위해 추가적인 편의한 메커니즘을 갖고 있을 수 있다.
- 특성
attributes : 이 노드가 Element라면, 이 노드가 가진 특성들을 포함한 NamedNodeMap. 아니면 null 반환.
childNode : 이 노드의 모든 자식들을 포함하는 NodeList. 자식이 없다면, 0개 노드를 포함하는 공백의 NodeList이다. 반환되는 NodeList의 컨텐츠는 "Live"하다. 즉, 노드 객체의 자식들에게 생긴 변화는 반환되는 NodeList 객체에 바로 반영된다. 즉, 노드 상태에 대한 정적인 스냅샷이 아니다. 이것은 getElementsByTagName 메서드에 의해 반환되는 것을 포함한 모든 NodeList에 대해 참이다.
firstChild : 노드의 첫번쨰 자식. 그러한 노드가 없다면, null 반환.
lastChild : 노드의 마지막 자식. 그러한 노드가 없다면, null 반환.
localName : // DOM Level 2에 추가
// XML 전용
namespaceURI : // DOM Level 2에 추가
// XML 전용
nextSibling : 이 노드의 바로 뒤에 존재하는 노드. 그러한 노드가 없다면, null 반환.
nodeName : 노드의 이름으로, nodeType에 따라 다르다.
nodeValue : 노드가 갖는 값으로, nodeType에 따라 다르다.
nodeType : 기반 객체의 타입을 나타내는 코드.
ownerDocument : // DOM Level 2에 추가
이 노드와 관련된 Document 객체. 새 노드를 생성하는 데에 사용되는 Document 객체이기도 하다. 이 노드가 Document와 함께 사용되지 않는 Document 또는 DocumentType 형의 객체라면, 이 값은 null이다.
parentNode : 해당 노드의 부모. Document, DocumentFragment, Attr을 제외한 모든 노드는 부모가 있다. 하지만 노드가 막 생성되어서 트리에 추가되지 않은 상태이거나, 트리에서 제거된 상태라면, 값은 null이다.
prefix : // DOM Level 2에 추가
// XML 전용
previousSibling : 이 노드의 바로 앞에 존재하는 노드. 그러한 노드가 없다면, null 반환.
- 메서드
appendChild : 이 노드의 자식 리스트 맨 뒤에 노드 newChild를 삽입한다. 만약 newChild가 이미 트리에 존재한다면, 우선 제거된다.
cloneNode : 이 노드의 복제본을 반환한다. 보통 노드에 대한 복사 생성자로 이용된다. 복제된 노드는 부모가 없어서 parentNode는 null을 반환한다.
Element를 복사하면 모든 특성과 값, 기본 특성값으로 나타내기 위해 XML 프로세서가 생성한 것까지 모두 복사한다. 하지만 텍스트는 자식인 Text 노드에 포함되지 떄문에, 깊은 복사가 아니라면 텍스트는 복사되지 않는다. 다른 타입의 노드를 복사하는 것은 노드의 단순하게 노드의 복제본으르 반환한다.
hasAttributes : // DOM Level 2에 추가
이 노드가 요소일 때, 특성을 갖고 있는지 여부를 반환한다.
hasChildNodes : 노드가 자식을 갖고 있는지 확인하기 위한 편의상의 메서드이다. 불린 값을 반환한다.
insertBefore : 이미 존재하는 자식 refChild의 앞에 newChild 노드를 삽입한다. refChild가 null이라면, newChild를 자식 리스트 맨 뒤에 삽입.
만약 newChild가 DocumentFragment 객체이면, newChild의 모든 자식들은 동일한 순서로 refChild 앞에 삽입된다. 만약 newChild가 이미 트리 상에 존재한다면, 우선 제거한다.
isSupported : // DOM Level 2에 추가
DOM 구현체가 특정 기능을 구현하는지, 그리고 해당 기능이 이 노드를 통해 지원되는지를 검사한다.
normalize // DOM Level 2에 추가
// XML 전용
replaceChild : 자식 리스트 안에서 자식 노드 oldChlid를 newChild로 교체하고, oldChild 노드를 반환한다. 만약 newChild가 이미 트리 상에 존재한다면, 우선 제거한다.
removeChild : 자식 리스트로부터 자식 노드 oldChild를 제거하고 반환한다.
> Interface NodeList
NodeList 인터페이스는 순서가 있는 노드들의 집합에 대한 추상화를 제공한다. 이때 집합이 구현되는 방식에 대한 규정이나 제약은 포함되지 않는다.
NodeList의 항목들은 0으로 시작하는 숫자 인덱스로 접근할 수 있다.
- 특성
length : 리스트 안의 항목 개수. 자식 노드 첨자의 유효 범위는 0부터 length - 1 까지이다.
- 메서드
item : 집합에서 index번째에 있는 항목을 반환한다. index가 리스트의 노드 개수보다 많거나 같으면 null을 반환한다.
> Interface NamedNodeMap
- 특성
length : 집합 안의 항목 개수. 자식 노드 첨자의 유효 범위는 0부터 length - 1 까지이다.
NamedNodeMap 인터페이스를 구현하는 객체는 이름을 통해 접근할 수 있는 항목의 집합들을 표현하는데 사용된다. NamedNodeMap은 NodeList를 상속하지 않음을 유의하자. NamedNodeMap는 특정한 순서를 갖고 있지 않다. NamedNodeMap를 구현하는 객체에 들어있는 객체들은 서수 첨자로 접근될 수 있지만, 이는 단지 NamedNodeMap의 항목들을 편리하게 열거할 수 있게끔 하기 위함이다. DOM은 안에 들어있는 노드에 대해 순서를 규정하지 않는다.
- 메서드
getNamedItem : 이름으로 특정되는 노드를 반환한다.
getNamedItemNS : // DOM Level 2에 추가
// XML 전용
local name과 네임스페이스 URI를 가진 노드를 반환한다.
item : index번째 항목을 집합에서 반환한다. index가 리스트의 노드 개수보다 많거나 같으면 null을 반환한다.
removeNamedItem : 이름으로 특정되는 노드를 제거한다. 만약 제거되는 노드가 default 값을 갖는 Attr이 경우, 즉시 대체된다.
removeNamedItemNS : //DOM Level 2에 추가
// XML 전용
setNamedItem : nodeName 특성을 사용하여 노드를 추가한다.
노드가 저장될 때에 쓰일 이름을 지정하는 데에 nodeName 특성을 사용하므로, 특정 타입("특별한" string값)을 값으로 갖는 노드가 2개 이상은 저장될 수 없다. 이름이 충돌하기 때문이다.
setNamedItemNS : // DOM Level 2에 추가
// XML 전용
> Interface CharacterData
CharacterData 인터페이스는 DOM 상의 문자 데이터에 접근하는 데에 사용되는 특성과 메서드를 갖도록 Node를 확장한다. 분명하게 말하자면, 이 집합에 대한 인터페이스는 이것을 사용하는 객체가 아닌 여기에서 정의된다. 비록 Text 등의 노드가 이 인터페이스를 상속하기는 하지만, CharacterData에 직접 대응하는 DOM 객체는 없다. 이 인터페이스의 모든 오프셋은 0에서 시작한다.
DOMString 인터페이스에서 설명했듯, DOM의 텍스트 string은 UTF-16으로 표현된다. 즉, 16bit 단위문자의 문자열이다. 앞으로 16bit 단위문자라는 용어를 통해 CharacterData에 대해 인덱싱할 때 한 문자가 16bit로 이루어짐을 나타낼 것이다.
- 특성
data : 이 인터페이스를 구현하는 노드의 문자 데이터. CharacterData 노드에 저장될 수 있는 데이터 양에 있어 DOM 구현체는 임의적 제한을 두지 않는다. 하지만 구현체의 제한은 노드가 갖는 데이터 전체가 단일 DOMString에 들어가지 못한다는 의미일 수 있다. 이런 경우, 사용자는 substringData를 호출하여 데이터를 적절한 사이즈의 조각으로 나누어야 한다.
length : data와 아래의 substringData 메서드를 통해 사용가능한 16bit 문자의 개수. 노드가 비어있을 경우 값으로 0을 가질 수 있다.
- 메서드
appendData : 인자로 받은 string을 노드의 문자 데이터 맨 뒤에 붙인다. 성공하면, 새로운 data는 기존의 data와 인자로 받은 string이 연결된 새로운 string으로 접근할 수 있도록 한다.
deleteData : 노드로부터 일정 범위의 16bit 문자들을 제거한다. 성공하면, data와 length는 변화를 반영한다.
insertData : 주어진 오프셋 위치에 인자로 받은 string을 삽입한다.
replaceData : 주어진 오프셋 위치에서 시작, 인자로 받은 string과 대체한다.
substringData : 노드로부터 일정 범위의 데이터를 추출한다
> Interface Attr
Attr 인터페이스는 Element 객체 안에서 특성을 표현한다. 특성으로서 허용 가능한 값들은 문서 타입 정의에 정의되어있다.
Attr 객체는 Node 인터페이스를 상속받지만, Attr 객체는 실제로는 자신이 묘사하는 요소의 자식 노드가 아니기 때문에, DOM은 Attr 객체를 문서 트리의 일부로 간주하지 않는다. 따라서 Attr 객체를 위한 Node 타입의 특성 parentNode, previousSibling, nextSibling은 모두 null 값을 갖는다. DOM은 특성이란 요소에 포함된 속성이라고 간주하지, 특성과 관련된 요소들로부터 분리된 고유성을 갖는다고 간주하지 않는다. 이것은 어떤 타입 요소가 갖는 디폴트 특성값과 같은 기능을 구현하는 데에 훨씬 효율적이다. 더 나아가, Attr 노드는 DocumentFragment의 직계 자식이 아닐 수도 있다. 하지만 DocumentFragmet 안에 있는 Element 노드와 관련이 있을 수 있다. 요약하면, 사용자와 DOM을 구현하는 사람은 Attr 노드가 Node 인터페이스를 상속받는 다른 객체들과 공유하는 무언가가 있을 수도 있음을 알아야 한다는 것이다. 하지만 이 둘은 꽤 이질적이기도 하다.
특성이 갖는 효과적인 값은 다음의 과정을 통해 결정된다.
1. 만약 해당 특성이 명시적으로 어떤 값을 할당받는다면, 그 값은 해당 특성을 위한 효과적인 값이다.
2. 그것이 아니라 만약 해당 특성을 위한 선언이 있었고 그 선언이 디폴트값을 포함한다면, 그 디폴트값은 해당 특성을 위한 효과적인 값이다.
3. 그것이 아니면, 해당 특성이 직접 명시적으로 추가되기 전까지는 구조 모델 상의 해당 요소에 존재하지 않는다.
XML에서는, 특성값으로 엔티티 참조가 포함될 수 있는데, Attr 노드의 자식 노드는 엔티티 참조가 확장되지 않는 표현 방식을 제공한다. 이 자식 노드는 Text 또는 EntitiyReference 노드이다. 특성 타입이 불명일 수 있기 때문에, 토큰화된 특성값은 없다.
- 특성
name : 해당 특성의 이름을 반환한다.
ownerElement : // DOM Level 2에 추가
이 특성이 포함된 요소를 가리킨다. 만약 다른 요소를 위해 사용되지 않는 특성이라면, null을 갖는다.
specified : 만약 원본 문서에서 해당 특성에 명시적으로 값이 주어졌을 경우, 이 특성은 true를 갖는다. 그렇지 않으면, false를 갖는다. 사용자가 아닌 구현체가 해당 특성에 대해 책임이 있음을 알아두자. 만약 사용자가 특성의 값을 변경하면 - 결국 디폴트값과 같은 값을 갖게 될 지라도 - specified 특성은 자동으로 true로 바뀐다. DTD에서 비롯된 디폴트값을 특성에 부여하기 위해, 사용자는 해당 특성을 제거해야 한다. 그러면 구현체에 의해 specified가 false로 부여되고 디폴트값이 부여된 새로운 특성이 만들어진다.
요약하자면:
- 만약 문서에 의해 특성에 할당된 값이 있다면, specified는 true가 되고, 특성값에는 값이 할당된다.
- 만약 특성에 할당된 값이 없고 디폴트값이 DTD에 있다면, specified는 false이고, 값은 DTD의 디폴트값이 부여된다.
- 만약 특성에 할당된 값이 없고 DTD로부터 비롯된 #IMPLIED 값을 갖고 있다면, 해당 특성은 문서의 구조 모델에 나타나지 않는다.
value : 반환할 때에, 특성의 값은 string으로 반환된다. 문자와 엔티티 참조는 해당하는 값으로 대체된다.
설정에서는, 이것은 파싱되지 않은 string로 이루어진 Text 노드를 생성한다.
> Interface Element
Element 인터페이스는 HTML 및 XML 문서 상의 요소를 표현한다. 요소는 자신과 관련된 특성들을 갖고 있을 수 있다. Element 인터페이스는 Node를 상속받기 때문에, Node 인터페이스의 generic 메서드 getAttributes를 이용하여 해당 요소가 갖는 모든 특성의 집합을 반환받을 수 있다. Element 인터페이스는 Attr 객체를 반환받는 2가지 메서드, 즉 특성 이름으로 받기 또는 특성값으로 받기를 갖고 있다. XML에서는, 특성값이 엔티티 참조를 갖고 있을 수 있기 때문에, 특성값을 표현할 만큼 충분히 복잡한 서브트리인지 검증하기 위해 Attr 객체가 반환되어야 한다. 반면 HTML에서는, 모든 특성이 간단한 string값을 갖고 있기 때문에, 특성값에 접근하는 메서드는 안전하고 편리하게 사용될 수 있다.
알아두기 : DOM Level 2에서는, normalize 메서드는 Node 인터페이스로 이동되고, 그곳으로부터 상속받는다.
- 특성
tagName : 요소의 이름. 예를 들어 아래의 예를 보자.
<elementExample id="demo">
...
</elementExample>
tagName 특성은 값으로 "elementExample"을 갖는다. 이 경우에 대해 XML은 다른 DOM 동작과 마찬가지로 대소문자를 구분한다는 것을 알아두자. HTML DOM의 경우 HTML 요소의 tagName을 반환할 때 기본적으로 대문자 형태로 반환하며, 이는 원본 HTML 문서 상의 대소문자 표기와는 상관없다.
- 메서드
getAttribute : 인자로 특성의 이름을 받고, 특성이 갖는 값을 반환한다.
getAttributeNS : // DOM Level 2에 추가
// XML 전용
getAttributeNode : 인자로 특성의 이름을 받고, 대응하는 Attr 노드를 반환한다.
getAttributeNodeNS : // DOM Level 2에 추가
// XML 전용
getElementsByTagName : 주어진 태그명을 가진 후손 요소들을 모두 담은 NodeList를 반환한다. 이때 순서는 Element 트리에 대해 전위 순회를 했을 경우의 순서이다.
getElementsByTagNameNS : // DOM Level 2에 추가
// XML 전용
hasAttribute : // DOM Level 2에 추가
인자로 특성의 이름을 받고, 해당하는 특성을 이 요소가 갖고 있거나, 디폴트값이 규정되어있을 경우 true를 반환한다. 그렇지 않으면 false를 반환한다.
hasAttributeNS : // DOM Level 2에 추가
// XML 전용
removeAttribute : 인자로 받은 이름을 가진 특성을 제거한다. 만약 제거된 특성에 대해 디폴트값이 존재한다면 즉시 해당 디폴트값으로 교체된다.
removeAttributeNS : // DOM Level 2에 추가
// XML 전용
removeAttributeNode : 특정 특성을 제거한다.
setAttribute : 새 특성을 추가한다. 만약 요소가 해당 이름을 갖는 특성을 이미 갖고 있을 경우, 그 특성값을 매개 변수로 받은 값으로 바꾼다. 이 값은 string이고, 이 값이 새로 부여될 때에는 파싱이 이루어지지 않는다. 따라서 마크업은 리터럴 문자로 취급되어, 새 값이 작성될 때에는 구현체에 의한 적절한 처리가 필요하다.
setAttributeNS : // DOM Level 2에 추가
// XML 전용
setAttributeNode : 새 특성을 추가한다. 만약 요소가 해당 특성을 이미 갖고 있을 경우, 해당 특성 노드를 새 특성 노드로 교체한다.
setAttributeNodeNS : // DOM Level 2에 추가
> Interface Text
Text 인터페이스는 Element 또는 Attr의 텍스트 컨텐츠를 표현한다. XML에서는 이를 문자 데이터라는 용어로 부른다. 만약 요소 컨텐츠 내부에 마크업이 없다면, 텍스트는 요소의 유일한 자식이자, Text 인터페이스를 구현하는 단일 객체 안에 포함된다. 마크업이 있다면, Element와 Text 노드의 리스트로 파싱되면서 해당 요소의 자식이 된다.
문서가 DOM을 통해 처리된 직후에는 각 텍스트 블록에 대해 단 하나의 Text 노드만을 갖는다. 사용자는 마크업을 거스르지 않고 주어진 요소의 내용을 표현할 수 있는 인접한 Text 노드를 생성한다. 하지만 사용자가 XML과 HTML 상에서 각 노드들 사이에 분리를 표현할 방법이 없기 때문에, DOM 편집 세션에 있어 특정 방향을 고집할 수는 없다는 것을 알고 있어야 한다. normarlize() 메서드를 Element에 사용하면 이처럼 인접한 Text 객체들을 한 블록 텍스트로 이루어진 단일 노드로 합칠 수 있다. 이것은 특정 문서 구조에 의존하는 동작 - XPointers를 이용한 탐색 등 - 을 수행하기 전에 권장된다.
- 메서드
splitText : Text 노드를 지정한 오프셋을 기준으로 두개 노드로 나누고, 두 노드는 트리 상에서 형제로 유지한다.
> Interface Comment
코멘트의 내용을 표현한다. 예를 들어 '<!--'와 '-->' 사이에 존재하는 모든 문자들을 표현한다. 비록 일부 HTML 도구는 완전하게 SGML 코멘트 구조를 구현하지만, 이것이 XML과 HTML의 코멘트를 정의한다는 것을 기억하자.